Conversation
| 3. Try hitting the test endpoint on the server, by navigating to `http://0.0.0.0:8443/hello` in your browser. | ||
| 4. Try running a packing on the server, by hitting the `http://0.0.0.0:80/pack?recipe=firebase:recipes/one_sphere_v_1.0.0` in your browser. | ||
| 3. Try hitting the test endpoint on the server, by navigating to `http://0.0.0.0:80/hello` in your browser. | ||
| 4. Try running a packing on the server, by hitting the `http://0.0.0.0:80/start-packing?recipe=firebase:recipes/one_sphere_v_1.0.0` in your browser. |
There was a problem hiding this comment.
These instructions were just slightly incorrect, this has nothing to do with the other code changes, I just ran into it when testing my code and I wanted to fix it
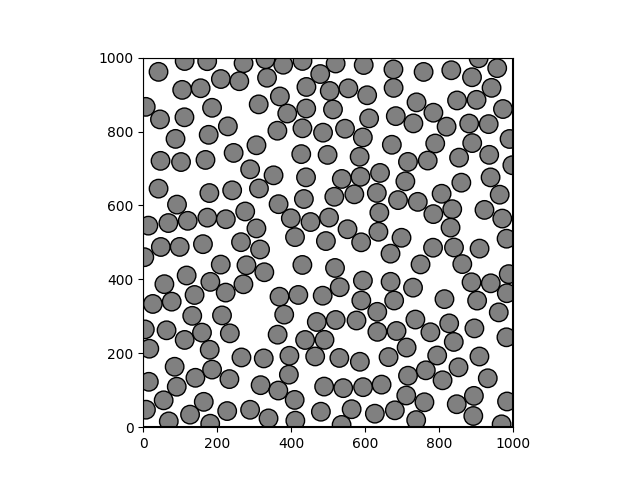
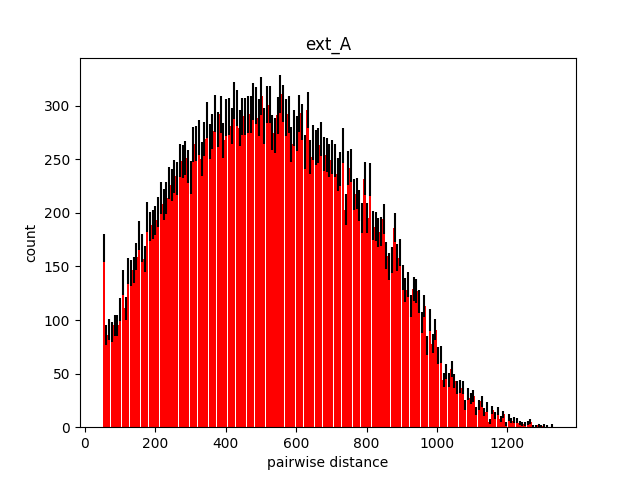
Packing analysis reportAnalysis for packing results located at cellpack/tests/outputs/test_spheres/spheresSST
Packing imageDistance analysisExpected minimum distance: 50.00
|

63ca5ae to
bd8ec42
Compare
Packing analysis reportAnalysis for packing results located at cellpack/tests/outputs/test_spheres/spheresSST
Packing imageDistance analysisExpected minimum distance: 50.00
|
* remove os fetch for job_id * use dedup_hash instead of job id * proposal: get hash from recipe loader * renaming and add TODOs * format * rename param to hash * remove unused validate param and doc strings in pack * simplify get_ dedup_hash * refactor job_status update * cleanup * fix upload_job_status to handle awshandler * pass dedup_pash to env for fetching across files * add tests * format1 * format test
* proposal: get hash from recipe loader * simplify get_ dedup_hash * only post simularium results file once for server job runs * update code for rebase * code cleanup --------- Co-authored-by: Ruge Li <rugeli0605@gmail.com>
* remove local metadata writes for auto-pop feature * remove cleanup firebase workflow * remove cleanup firebase code * 1. make doc url a constant 2.remove unused param
| config = request.rel_url.query.get("config") | ||
| job_id = str(uuid.uuid4()) | ||
|
|
||
| dedup_hash = DataDoc.generate_hash(body) |
There was a problem hiding this comment.
check if this causes an error in the case that recipe was passed in as a firebase path
| return initialized_db | ||
| return None | ||
|
|
||
| def job_exists(self, dedup_hash): |
There was a problem hiding this comment.
might be worth adding a comment describing this function
There was a problem hiding this comment.
Two major changes in this file:
- We now accept the recipe as either a firebase path in the
recipeURL parameter (as we always have) OR as a JSON object in the body of the packing request. Either way, it will be passed along to thepackfunction. - Instead of generating an unique id to be the job ID, we calculate the dedup hash for the recipe and use that as our job ID. We check this dedup hash against those existing in the job_status firebase collection to see if this exact recipe has already been packed, and if we find a match, we return it rather than running the packing
There was a problem hiding this comment.
Three notable changes here:
recipeargument can now be a dictionary representing the recipe, instead of just a file path or a firebase path which were previously supported. If it's a dictionary, we initialize the recipe loader usingRecipeLoader.from_json, then everything else is the same- We're now using
dedup_hashinstead ofjob_id. We had previously been storingjob_idas an environmental variable, which was kinda hacky, so now we're just passingdedup_hashin directly and passing it along in place ofjob_idfor packings initiated from server.py validatewas no longer being used, so we just removed it from the argument list. This was an artifact from a separate PR that we just noticed here, so we're cleaning it up
There was a problem hiding this comment.
RecipeLoader needs to now accept a dictionary representing a JSON recipe, while maintaining the previous functionality for accepting an input_file_path. Fortunately didn't take much to make this work! But a few things of note
- I didn't know how best to change / document that RecipeLoader can be initialize with either a input_file_path OR a json_recipe, not both, but you need to have one. To try to clarify this, I made the
from_jsonclass method as the avenue to initialize a RecipeLoader with a JSON recipe, but I'm not sure if that's more clear or just more confusing. Open to feedback / suggestion on this - to make
_readwork for json_recipes, we just had to add some default values and skip the part where we do the initial recipe read if we have a json_recipe loaded in
There was a problem hiding this comment.
Major changes here:
- We realized the
resultscollection in firebase is not necessary. For cellpack studio purposes, it is redundant withjob_statusand we only look tojob_status. For locally run packings, we can skip uploading the result path to firebase at all and just directly open the simularium file. This allowed us to removestore_metadataand simplifystore_result_file - We had been storing job_id as an environmental variable for packings initiated from server.py, which was kinda hacky. Now, we are directly passing in dedup_hash, which is used as our identifier for server packings
There was a problem hiding this comment.
Major changes here:
- We realized the results collection in firebase is not necessary. For cellpack studio purposes, it is redundant with job_status and we only look to job_status. For locally run packings, we can skip uploading the result path to firebase at all and just directly open the simularium file. This allowed us to remove the whole
ResultDocclass, theDBMaintenanceclass, and removeupload_result_metadata - We're now using
dedup_hashinstead ofjob_idas the id for server packings - Refactored
upload_job_statusto handle the functionality ofupdate_outputs_directorysince they were basically the same, and removedupdate_outputs_directory
There was a problem hiding this comment.
We realized the results collection in firebase is not necessary. For cellpack studio purposes, it is redundant with job_status and we only look to job_status. For locally run packings, we can skip uploading the result path to firebase at all and just directly open the simularium file. This allowed us to remove the cleanup code for the results collection (which was the only firebase cleanup we were doing in this repo anyways)
| simularium_url = None | ||
| for url in public_urls: | ||
| if url.endswith(".simularium"): | ||
| simularium_url = url |
There was a problem hiding this comment.
We had previously uploaded the result .simularium file twice for server run packings! To avoid that, now we're finding it in the uploaded outputs directory and keeping track of it's path to specifically reference in the job_status entry
There was a problem hiding this comment.
We realized the results collection in firebase is not necessary. For cellpack studio purposes, it is redundant with job_status and we only look to job_status. For locally run packings, we can skip uploading the result path to firebase at all and just directly open the simularium file. This allowed us to remove the cleanup code for the results collection (which was the only firebase cleanup we were doing in this repo anyways)
There was a problem hiding this comment.
We realized the results collection in firebase is not necessary. For cellpack studio purposes, it is redundant with job_status and we only look to job_status. For locally run packings, we can skip uploading the result path to firebase at all and just directly open the simularium file.
Problem
Currently, when a user wants to pack an edited recipe via the cellpack client, we upload the edited recipe to firebase, pass that reference to the server, and then the server retrieves the recipe from firebase. To minimize firebase calls and improve efficiency of the client, we're changing that flow to instead send the edited recipe JSON as the body of the packing request to the server.
We also wanted a way to check if we have already packed a recipe and if we have, return that result file rather than running the whole packing again. To do this, we are calculating a hash for the recipe objects before they are packed. The hash for each recipe will be uploaded to firebase along with its result files, so we can query firebase for a given hash to see if that recipe has a packing result already.
Solution
Added in the functionality for the server to read the recipe data from the request body, instead of only being able to handle firebase paths or local file paths. We are still keeping the functionality of reading recipes from firebase paths and local file paths of course, so nothing should change for those use cases.
We use the existing dedup_hash() function to calculate a hash for each recipe coming in to the server. We check if there is a result (or a job that's already running) for that hash in the
job_statuscollection in firebase, and if so, we just return that reference rather than initiating a new packing. This dedup hash is now used as the unique identifier for the packing, rather than generating a UUID.We also realized that we don't need the results collection in firebase, so we removed it. For cellpack studio purposes, it contained all redundant information to the job_status collection, so having both collections was redundant and a little confusing. For locally run packings, its unneeded.