


Performance is a function of what you control. So I control all of it.
Research software engineer building bare-metal, high-performance systems — and using them as instruments to investigate hard problems. CUDA, Rust and C/C++ where latency and control decide the outcome; Python where it pays. AI runs through it both ways: systems that run models, and systems built with models (neural-guided annealers, compile-time-safe neural interfaces, forecasting control loops). Solo, end to end, on bare metal (Arch Linux, CUDA-first) — with benchmarks anyone can re-run. The hardware is a tool I command, not a limit: the skill is the architecture under the metal, and it moves across whatever the silicon is — an edge board, a single GPU, a cluster. (NVIDIA by preference — CUDA, CUDA-Q, tensor cores, Blackwell.)
Systems first, always — but driven by research. The fields below — quantum, neuroscience, materials, energy — are proving grounds for the same skill, not the identity. Not a neuroscientist or a materials physicist; the engineer who builds the systems to investigate them at the metal, and who cares enough to get the physics right and the numbers honest. The through-line: physics computes by minimizing energy; the systems here exploit it.
Stack: CUDA (hand-written kernels, sm_120 roofline) · Rust (control loops, systems) · C / C++17 (compile-time guarantees) · Python (AI/ML, analysis). AI is a first-class layer, not glue. No cloud, by choice.
Flagship — SUBSTRATE: can I make the metal go fast — and prove it?
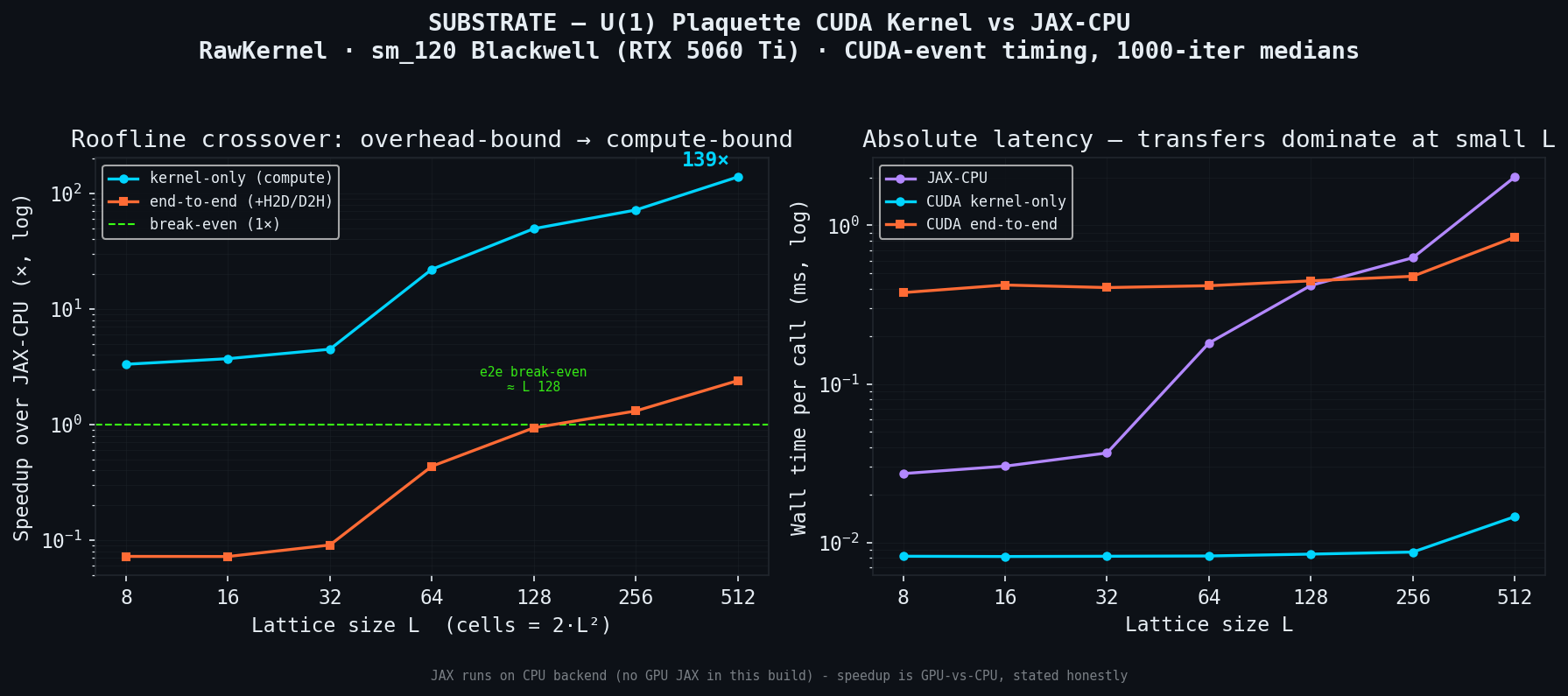
A multi-physics / bio-electromagnetics simulation engine. The physics is the hard problem; the point is the engine underneath: hand-written CUDA (sm_120) with an honest, kernel-only roofline — measured on a Blackwell sm_120, re-runnable on any CUDA GPU; end-to-end break-even stated, not hidden — plus tensor-network solvers for many-body systems. Start here if you want to know whether I can write fast kernels and back the numbers.
BLACKWALL · ICEPICK · FLATLINE — the silicon, reverse-engineered. A three-part Blackwell (sm_120) teardown, hand-written CUDA: the compute roofline (BLACKWALL), the microarchitecture beneath it — instruction latencies, caches, the SASS the compiler actually emits (ICEPICK), and the energy/thermal wall (FLATLINE). The metal, measured directly — compute · communication · energy.
Blaze — GPU compression for massive scientific & quantum data. Tensor-Train / MPS compression, GPU SVD, MPS↔circuit bridge. The specialist tool the rest of the ecosystem leans on.
AETHER — hard physics, implemented correctly. Computational-materials lab: electronic structure, the full topological set (SSH, Haldane, Kane–Mele), metamaterials, GPU-accelerated solvers, inverse design. ~90 tests; every claim checked against a closed form. Correctness isn't optional.
KHAOS — real-time systems where safety is enforced, not hoped for.
Closed-loop BCI kernel: a CUDA DSP hot-path, stimulation limits guaranteed by the C++ compiler
(static_assert), three independent safety layers, post-quantum audit ledger. Sub-100 µs is the
design target — marked unverified until benchmarked end-to-end.
HELIOS — control loops that can't go down. 24/7 predictive DC-microgrid controller. Rust MPPT loop (100 ms tick), CNN-LSTM forecasting, post-quantum trust anchors. Where the lights actually have to stay on.
DRIFT — the structure under the problem. Optimization, self-assembly and neural memory (Hopfield) read as ground states of one Ising Hamiltonian — the unification thesis, made measurable and benchmarked against the Landauer floor of computation.

More in the repos — same spine, other proving grounds. Everything reproducible; the metal is a tool, not the point.