diff --git a/mkdocs.yml b/mkdocs.yml
index 2fc74935a..35c6af27e 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -75,7 +75,7 @@ plugins:
categories_url_format: "{slug}"
archive: false
categories_name: Blog
- categories_sort_reverse: true
+ # categories_sort_reverse: true
- social:
cards_layout_options:
background_color: "black"
diff --git a/mkdocs/assets/stylesheets/cloudscape-docs.css b/mkdocs/assets/stylesheets/cloudscape-docs.css
index cabeb93b9..5a6ed09e4 100644
--- a/mkdocs/assets/stylesheets/cloudscape-docs.css
+++ b/mkdocs/assets/stylesheets/cloudscape-docs.css
@@ -1861,6 +1861,7 @@
}
.md-typeset :is(h1, h2, h3, h4, h5, h6) a:hover {
text-decoration: underline;
+ color: inherit; /* keep the heading color — don't pick up Material's accent (lilac) on hover */
}
/* Blog excerpt header (author avatars + date · category · read time) removed entirely on the
@@ -1875,31 +1876,13 @@
}
/* ===== Blog post (article) layout ========================================== */
-/* Blog posts render NO left sidebar (overrides/blog-post.html) — only the article + right rail.
- The content div carries .md-content--blog (NOT Material's .md-content--post, which is a
- column-reverse flex meant to pair the post sidebar with the article). It's a CSS hook to widen
- the article to the same "collapsed left menu" layout as a docs page with the nav hidden: a
- 1280px region (960 body + 40 gap + 280 rail) centered in the viewport. :has() reaches ancestors. */
+/* Blog posts use the same desktop layout as the blog index/category pages: left nav sidebar +
+ article + right rail (On this page, then the relocated post metadata). The content div carries
+ .md-content--blog purely as a hook for that metadata relocation (see .cs-post-meta); layout-wise
+ it now matches a normal page, so no width/sidebar overrides are needed here. */
@media screen and (min-width: 76.1875em) {
- .md-main__inner.md-grid:has(.md-content--blog) {
- max-width: 1280px;
- margin-left: auto;
- margin-right: auto;
- }
- .md-main__inner:has(.md-content--blog) .md-content {
- margin-left: 0;
- }
- .md-main__inner:has(.md-content--blog) .md-sidebar--secondary {
- margin-right: 0;
- }
- /* Blog posts render the primary nav only so the mobile drawer (burger) has it; on desktop the
- article spans the full width, so hide the left sidebar here. */
- .md-main__inner:has(.md-content--blog) .md-sidebar--primary {
- display: none;
- }
- /* No left sidebar → drop the full-height vertical divider drawn at left:280px. Applies to blog
- posts and to any page that hides the nav (e.g. /terms, /privacy → .md-sidebar--primary[hidden]). */
- body:has(.md-content--blog)::before,
+ /* Pages that hide the nav entirely (/terms, /privacy → .md-sidebar--primary[hidden]) have no
+ left sidebar, so drop the full-height vertical divider drawn at left:280px. */
body:has(.md-sidebar--primary[hidden])::before {
display: none;
}
diff --git a/mkdocs/blog/posts/state-of-cloud-gpu-2025.md b/mkdocs/blog/posts/state-of-cloud-gpu-2025.md
index b9add7915..81f238785 100644
--- a/mkdocs/blog/posts/state-of-cloud-gpu-2025.md
+++ b/mkdocs/blog/posts/state-of-cloud-gpu-2025.md
@@ -4,8 +4,8 @@ date: 2025-09-10
description: "TBA"
slug: state-of-cloud-gpu-2025
image: https://dstack.ai/static-assets/static-assets/images/cloud-gpu-providers.png
-# categories:
-# - Benchmarks
+categories:
+ - Reports
---
# The state of cloud GPUs in 2025: costs, performance, playbooks
diff --git a/mkdocs/blog/posts/state-of-heterogeneous-compute-2026.md b/mkdocs/blog/posts/state-of-heterogeneous-compute-2026.md
new file mode 100644
index 000000000..22065de67
--- /dev/null
+++ b/mkdocs/blog/posts/state-of-heterogeneous-compute-2026.md
@@ -0,0 +1,177 @@
+---
+title: "The state of heterogeneous AI compute in 2026"
+date: 2026-06-26
+description: "How supply, power, software readiness, orchestration, and networking shape accelerator choices across NVIDIA, AMD, TPUs, Trainium, and specialized inference systems."
+slug: state-of-heterogeneous-compute-2026
+image: https://dstack.ai/static-assets/static-assets/images/state-of-heterogeneous-compute-2026.png
+categories:
+ - Reports
+---
+
+# The state of heterogeneous AI compute in 2026
+
+Heterogeneous AI compute is becoming harder to ignore. The reason is practical: supply pressure, pricing, and stack readiness are making more than one accelerator path worth evaluating.
+
+*Disclosure: dstack is an open-source control plane for AI workloads, which shapes our interest in the orchestration layer below. We've kept the rest of this report vendor-neutral.*
+
+
+
+This report focuses on accelerator choices behind training and inference workloads: the main patterns, the evidence behind them, how readiness differs, and why orchestration and networking determine whether capacity can be used in practice.
+
+
+
+## Patterns
+
+Heterogeneous compute has two dimensions: how capacity is pooled, and where execution crosses hardware boundaries. Separate pools are operationally tractable; one training run or one inference request spanning unlike stacks requires much more validation. The patterns below are roughly ordered from most practical to most experimental.
+
+| Pattern | What it means |
+| :---- | :---- |
+| **Same stack, different generations** | Multiple generations of one vendor's stack: H100→GB300, MI300X→MI355X, TPU v5p→Ironwood, or the Trainium line. The runtime carries over, but memory, interconnect, availability, and tuning differ by generation. |
+| **Different stacks, separate workloads** | Training, fine-tuning, evaluation, batch inference, and online inference run on different accelerator stacks depending on supply, cost, and readiness. This is the most practical cross-stack pattern because each workload keeps its own runtime, image, kernels, and failure modes. |
+| **Requests routed across stacks** | One user-facing endpoint routes whole requests to complete deployments, each on its own accelerator stack. This uses mixed capacity without splitting a single inference; each deployment must still meet the same behavior, context, latency, and fallback requirements. |
+| **One training run across sites** | One training run spans clusters, regions, or datacenters, usually within the same accelerator and collective stack. This is capacity and fabric engineering, not generic portability; cross-vendor training remains frontier for most teams. |
+| **One inference request across stacks** | Prefill/decode split across unlike accelerator stacks is emerging. The phases stress compute, memory bandwidth, and networking differently, but public evidence is mostly research or partner-specific. Assume experimental until the exact serving path is demonstrated. |
+
+## Drivers
+
+Most accelerator decisions come down to a few practical questions: whether the team can get the right capacity, whether there is power to run it, and whether the software stack is ready for the workload.
+
+### Supply
+
+Accelerator choice is now part of capacity planning, not just performance tuning. The question is often how soon a team can get the right cluster shape, in the right region, with the right interconnect, quota, reservation terms, and price. Teams look at alternatives when the most familiar path means waiting too long, committing too much, or accepting capacity that does not fit the workload. The public signals below show supply strategy, not neutral performance proof.
+
+| Organization | Public figures | What it supports |
+| :---- | :---- | :---- |
+| **Anthropic** | Up to 1M [Google Cloud TPUs](https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services); up to 5 GW of additional [AWS capacity using Trainium](https://www.anthropic.com/news/anthropic-amazon-compute) | Frontier labs are willing to run across cloud-owned accelerator stacks when capacity and economics justify it. |
+| **OpenAI** | At least 10 GW of [NVIDIA systems](https://investor.nvidia.com/news/press-release-details/2025/OpenAI-and-NVIDIA-Announce-Strategic-Partnership-to-Deploy-10-Gigawatts-of-NVIDIA-Systems/default.aspx); 6 GW of [AMD GPUs](https://openai.com/index/openai-amd-strategic-partnership/) | Even the largest NVIDIA buyers are also pursuing merchant alternatives. |
+| **Meta** | Up to 6 GW of [AMD Instinct GPUs](https://ir.amd.com/news-events/press-releases/detail/1279/amd-and-meta-announce-expanded-strategic-partnership-to-deploy-6-gigawatts-of-amd-gpus) | Large buyers are adding non-NVIDIA merchant GPUs to their supply plans. |
+
+### Power
+
+At frontier scale, the limit is increasingly power, not chips. Getting accelerators also means getting power to run them, a grid connection, and cooling, each with its own multi-year lead time. That is why the deals above are sized in gigawatts.
+
+The racks are dense enough that liquid cooling is now required, not optional. [NVIDIA's GB300 NVL72](https://www.nvidia.com/en-us/data-center/gb300-nvl72/) draws about 135 kW; a full [Ironwood](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) pod is close to 10 MW; AMD's MI355X and coming Helios racks are in the same class.
+
+| Rack / chip | Power | Cooling |
+| :---- | :---- | :---- |
+| **NVIDIA GB300 NVL72** | ~135 kW per rack (~155 kW peak) | ~90% liquid; air not viable |
+| **TPU v7 (Ironwood)** | ~600 W per chip; ~10 MW per 9,216-chip pod | Liquid-cooled at pod scale |
+| **AMD MI355X / Helios** | High-density rack class | Liquid-cooled |
+
+So capacity planning is now also power planning, which favors buyers who control power and data-center space. It does not remove the software requirement: the stack still has to be ready.
+
+### Software
+
+An accelerator path is only relevant when the software stack is ready for the workload. The key checks:
+
+- **Baseline.** NVIDIA remains the reference path for kernels, collectives, containers, debugging, profiling, and operator experience.
+- **Runtime path.** AMD means ROCm/RCCL validation; TPUs mean XLA/JAX/PyTorch/XLA and Cloud TPU operations; Trainium means Neuron, compiler behavior, framework support, and AWS deployment paths.
+- **Serving path.** TensorRT-LLM, Triton Inference Server, Dynamo, vLLM, and SGLang matter because serving support is model-, backend-, and feature-specific. Gateways route across qualified backends; they do not make stacks interchangeable.
+- **Model path.** Attention kernels, quantization, precision, compiler behavior, and model-specific support can decide whether the workload is usable on a given accelerator.
+- **Specialized systems.** Groq and Cerebras are evaluated through supported models, latency, output speed, context support, deployment path, and price rather than as general-purpose accelerator pools.
+
+## Benchmarks
+
+This is not a ranking of accelerators. Benchmark evidence is useful when it says something concrete about the system, workload, precision, scale, and software path being evaluated.
+
+| Benchmark | What it shows | What it does not prove |
+| :---- | :---- | :---- |
+| **[MLPerf Training v6.0](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/)** | Standardized training submissions are broadening: 95 submitted systems, 13 accelerator types, 24 submitting organizations, and 60% multi-node systems. | That a vendor is ready for every training stack, model architecture, provider image, or cluster shape. |
+| **[MLPerf Inference v6.0](https://mlcommons.org/2026/04/mlperf-inference-v6-0-results/)** | Inference benchmarks are moving toward modern workloads, including new or updated datacenter tests and more multi-node submissions. | That service latency, cost, routing, KV cache behavior, or production failure modes will match the benchmark. |
+| **Vendor MLPerf writeups: [NVIDIA](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/), [AMD](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html)** | Configuration details and vendor interpretation, such as NVIDIA's Training v6.0 sweep or AMD's MI355X above 1M tokens/sec in Inference v6.0. | A neutral cross-vendor summary; the vendor chooses what to emphasize. |
+| **[SemiAnalysis InferenceX](https://inferencex.semianalysis.com/)** | Market and software movement as serving engines, kernels, quantization, and runtime choices improve, especially across NVIDIA and AMD GPU stacks. | A standardized benchmark suite or a complete market map across TPUs, Trainium, Groq, Cerebras, Tenstorrent, or every deployment path. |
+
+## Vendors
+
+Readiness turns theoretical supply into usable capacity: the question is not whether an accelerator exists or benchmarks well, but whether a team can use it for training or inference without making the accelerator choice the project. This section looks at each accelerator through three lenses: adoption profile, deployment flexibility, and readiness.
+
+### Adoption profiles
+
+Adoption profile describes where an accelerator is practical today.
+
+| Adoption profile | Meaning |
+| :---- | :---- |
+| **Broad adoption** | Broad software support, public availability, familiar operations, and minimal rewrites. |
+| **Early adopters** | More validation work is acceptable if the upside is large enough. |
+| **Cloud-committed** | One hyperscaler runtime is acceptable, with lower portability. |
+| **Specialized** | Supported models, latency, output speed, context, and price dominate. |
+
+!!! info "Frontier buyers"
+
+ For frontier buyers such as Anthropic, OpenAI, and Meta, supply is part of accelerator strategy, and the entry point differs by workload. Merchant alternatives like AMD come in through inference, while frontier training stays on NVIDIA or a deeply co-designed cloud stack (Anthropic has publicly committed to large-scale TPU and Trainium capacity to train and serve Claude, with the exact split inferred from those deals rather than disclosed).
+
+Deployment flexibility means whether the accelerator can be owned, rented, used through a specialized path, or used through one cloud stack.
+
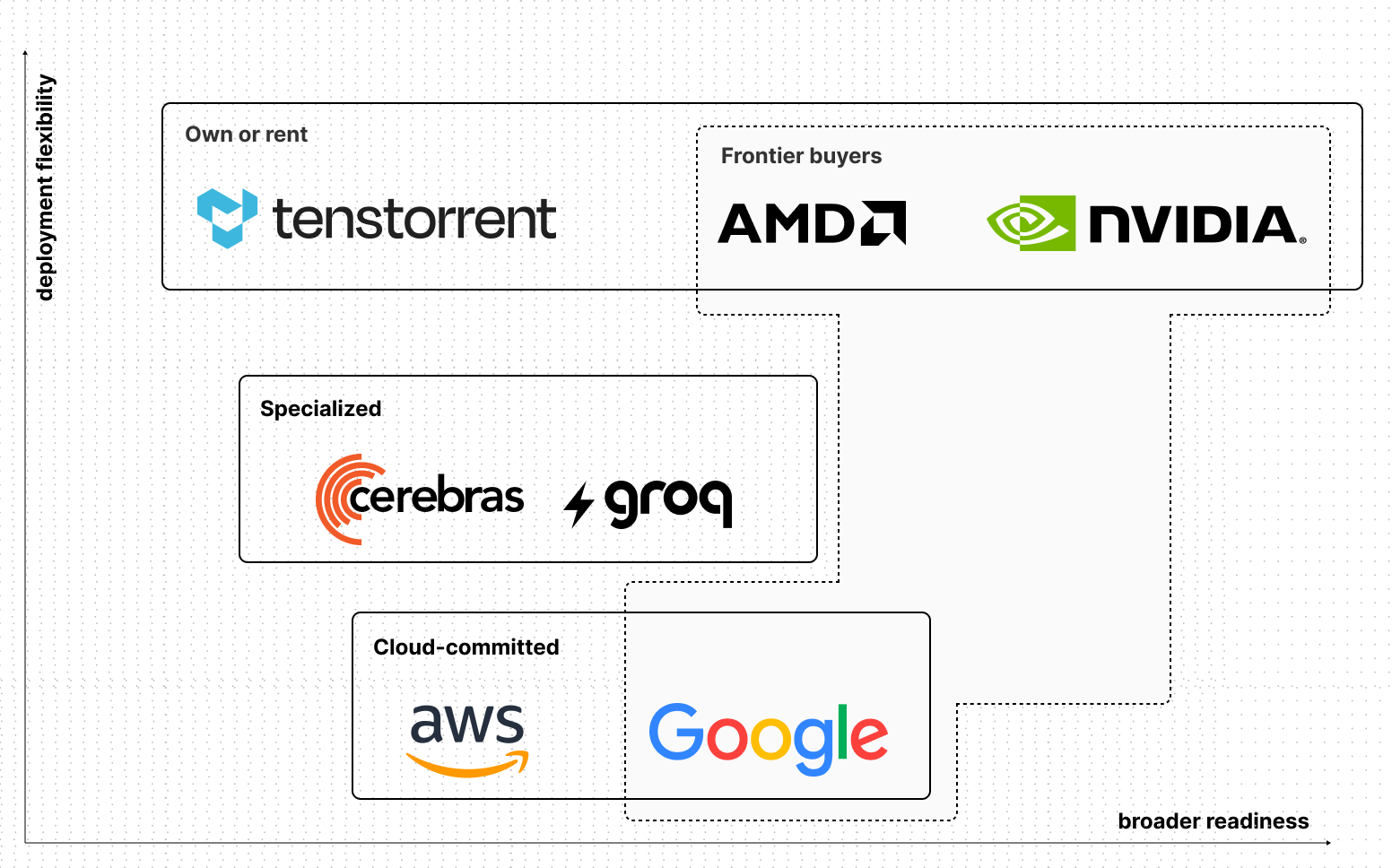
+### Vendor categories
+
+| Category | Vendors | Why it is placed there |
+| :---- | :---- | :---- |
+| **Open market** | NVIDIA, AMD, Tenstorrent | Higher deployment flexibility: these accelerator paths are available outside one cloud owner. NVIDIA and AMD have broader public software and workload evidence; Tenstorrent remains earlier and more vendor-led. |
+| **Specialized inference** | Groq, Cerebras | Medium deployment flexibility: not cloud-owned, but narrower and optimized for supported inference models. Readiness depends on latency, output speed, context, price, and vendor stack fit rather than broad CUDA/ROCm/XLA/Neuron or vLLM/SGLang coverage. |
+| **Cloud-owned** | Google TPUs, AWS Trainium | Lower deployment flexibility: these accelerator paths are rented through the cloud that owns the chip and runtime. The trade-off is portability, not whether the stack is useful; both can be strong when the cloud commitment is acceptable. |
+
+### Vendor readiness
+
+| Vendor | Fits | Readiness signal | Main constraint |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA** | Direct accelerator use across training, fine-tuning, batch inference, and self-hosted online inference in public clouds and private clusters. | The depth of the [CUDA](https://docs.nvidia.com/cuda/) ecosystem: kernels, [NCCL](https://docs.nvidia.com/deeplearning/nccl/), [TensorRT-LLM](https://docs.nvidia.com/tensorrt-llm/), [Triton](https://docs.nvidia.com/deeplearning/triton-inference-server/index.html), [Dynamo](https://www.nvidia.com/en-us/ai/dynamo/), and the broadest tooling and provider support, plus the only clean sweep in [MLPerf Training v6.0](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/) (the lone platform to submit on every test). | Cost and access. NVIDIA is premium-priced and supply is contended, so commitment terms and fabric availability often gate a team more than performance does. |
+| **AMD** | Merchant GPU path outside an NVIDIA-only plan, with validation on the exact workload instead of assuming CUDA compatibility. | The strongest non-NVIDIA case. MI355X cleared 1M tokens/sec in [Inference v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html) with 288GB HBM3e (50% over B200); its first multi-node [Training v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-training-6-0-results.html) submission came within ~6% of B200 on the LLM tests, on [ROCm](https://rocm.docs.amd.com/en/latest/index.html)/[RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html). | Software, not silicon. ROCm performance depends on the serving engine and version (on several current open-model benchmarks SGLang has led vLLM, though leadership shifts by model and release); training trails inference; and cloud availability, though growing, is narrower than NVIDIA's. |
+| **Tenstorrent** | Early adopters evaluating a direct accelerator path that is not tied to CUDA or a hyperscaler-owned runtime. | The [Galaxy Blackhole launch](https://tenstorrent.com/en/newsroom/tenstorrent-enables-ai-at-scale-with-industry-leading-performance), where Tenstorrent reports deployed superclusters, LLM and video-generation workload claims, and a stack built around TT-Metal, TT-NN, TT-Forge, and TT-MLIR. | Software maturity and access. Inference runs through Tenstorrent's [vLLM fork](https://github.com/tenstorrent/vllm) on a validated, per-gen model list (not day-0), with no established training or disaggregated-serving path. Capacity is mostly direct purchase, not in clouds. Hardware is real and the stack is open; treat the software as early. |
+| **TPU** | Google Cloud-anchored workloads that can build around XLA, JAX, PyTorch/XLA, and Cloud TPU infrastructure. | [Ironwood (TPU v7)](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) is GA, and large-scale production use (e.g. Anthropic) is the main readiness signal. | Access and lock-in. Capacity is quota-gated and still ramping externally; GCP-only; model support is XLA/JAX-first, so day-0 coverage can lag; and there's little neutral benchmark evidence for Ironwood. The economics can still win on TCO. |
+| **Trainium** | AWS-committed workloads that can build around [Neuron](https://awsdocs-neuron.readthedocs-hosted.com/) rather than treating it as a drop-in GPU replacement. | [Trainium3 UltraServers](https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-ec2-trn3-ultraservers/) are GA as system-scale infrastructure, and Anthropic runs production training on Trainium, the main readiness signal. | Software and evidence. Neuron's compiler/runtime is the gating gap versus CUDA, and with no neutral benchmark (AWS doesn't submit to MLPerf) readiness rests on AWS's numbers and Anthropic's use. AWS-only, with day-0 model coverage tied to Neuron. |
+| **Groq and Cerebras** | Specialized cases for supported inference models, where latency, output speed, context, and price matter more than general accelerator access. | Service-level results (throughput, time-to-first-token, context), not general benchmarks. Cerebras publishes current numbers across [Gemma 4](https://www.cerebras.ai/blog/gemma-4-on-cerebras-the-fastest-inference-is-now-multimodal) and GPT-OSS 120B. | Inference-only, with curated (not day-0) model support, so you're betting on the vendor's roadmap. Those bets now diverge: Groq is entangled with NVIDIA after its [December 2025 deal](https://www.networkworld.com/article/4112131/nvidia-licenses-groqs-inferencing-chip-tech-and-hires-its-leaders.html); Cerebras stays independent (recent [IPO](https://www.theregister.com/ai-ml/2026/05/15/cerebras-wafer-scale-ai-bet-delivers-blockbuster-ipo/5240821)). |
+
+## Orchestration
+
+Orchestration is more than a scheduler queue. It lets teams describe training jobs, batch jobs, and services (images, resources, placement) once, then handles the operational work of running them: provisioning, scaling, retries, and recovery. What it cannot remove is compatibility: CUDA, ROCm, XLA, Neuron, collective libraries, serving engines, and kernels are not interchangeable, so the control plane matches each workload to capacity that can actually run it.
+
+| Stack | Role and trade-off |
+| :---- | :---- |
+| **Kubernetes** | Strong substrate for containers, services, operators, and internal platforms. For AI, it often requires stitching together device plugins, vendor GPU operators, Dynamic Resource Allocation, Kueue or Volcano, Kubeflow, KubeRay, autoscaling, and serving layers. Kubernetes-native multi-cluster tooling helps when capacity is already Kubernetes, but it still leaves accelerator discovery, quotas, procurement, runtime images, and cross-cloud placement as platform work. |
+| **Slurm** | Strong for large batch clusters, queueing, accounting, policy, and topology-aware placement. The limits are cloud-native and container-native workflows: real deployments often depend on local modules, queues, prolog/epilog scripts, plugins, and launch conventions. NVIDIA's SchedMD acquisition also makes Slurm vendor independence something teams should watch. |
+| **Emerging** | AI-native control planes such as `dstack` and SkyPilot focus on making scattered accelerator capacity usable through higher-level workload definitions for training jobs, batch jobs, and services. They reduce the glue work created by fragmented clouds, clusters, accelerators, runtimes, and sites, which otherwise falls to platform teams. They still depend on each accelerator stack and serving runtime for kernels, images, collectives, routing, and performance. |
+
+**Distributed inference.** Runtimes such as SGLang, Dynamo, vLLM, Mooncake, and NIXL handle routing, batching, prefill/decode behavior, and KV cache movement; orchestration deploys and runs those setups across compatible capacity.
+
+**RL post-training.** One job runs a training stack (FSDP/Megatron) and a generation stack (vLLM/SGLang) at once, with the trainer pushing fresh weights to the rollout workers every step. [Ray](https://github.com/ray-project/ray) has become the common foundation here: it co-schedules the trainer and rollout roles, colocated or split across pools, and keeps the weight sync from stalling each step.
+
+!!! info "Vendor independence"
+ The orchestration and control-plane layer should not quietly become another accelerator dependency. NVIDIA acquired [Run:ai](https://blogs.nvidia.com/blog/runai/), a Kubernetes-based workload management platform, and [SchedMD](https://blogs.nvidia.com/blog/nvidia-acquires-schedmd/), the leading developer of Slurm. NVIDIA says Slurm will remain open-source and vendor-neutral, and its Run:ai messaging emphasizes choice and flexibility. Teams may still trust those projects, but heterogeneous compute makes vendor independence a practical requirement for the scheduler and control plane.
+
+## Networking
+
+For training, the practical case is usually one accelerator stack spread across sites, regions, or generations. The job still depends on a matching collective-communication library: [NCCL](https://docs.nvidia.com/deeplearning/nccl/) for NVIDIA, [RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html) for AMD, and cloud-specific fabrics for TPUs and Trainium. Full-system results such as [MLPerf Training](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/) help confirm that a single-stack cluster scales; they do not make cross-vendor training portable.
+
+The key difference is the scale-up domain: how many accelerators sit in one fast, tightly connected pool before traffic has to cross a slower network.
+
+| Stack | Scale-up domain | Per-accelerator bandwidth | Interconnect |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA Vera Rubin NVL72** | 72 GPUs (one rack, 2H 2026) | 3.6 TB/s per GPU | NVLink 6, all-to-all |
+| **AMD Helios (MI455X)** | 72 GPUs (one rack, 2H 2026) | ~0.9 TB/s per GPU | UALink over Ethernet |
+| **TPU v7 (Ironwood)** | up to 9,216 chips (pod) | ~1.2 TB/s per chip | ICI 3D torus + optical switching |
+| **AWS Trainium3** | 144 chips (Trn3 UltraServer) | ~2 TB/s per chip | NeuronLink all-to-all |
+
+GPU racks and Trainium keep their fast domains in the dozens to ~150 accelerators; only TPU's torus reaches the thousands. The two GPU racks are about even on total bandwidth (~260 TB/s), but NVIDIA's per-GPU link is roughly 4x AMD's, which matters for training. None of this makes the stacks interchangeable, and a 9,216-chip pod only helps if the model can actually use it.
+
+For inference, the practical case is disaggregated serving within a compatible stack: prefill workers, decode workers, routing, and a path to move the KV cache. NVIDIA's [Dynamo disaggregated serving](https://docs.nvidia.com/dynamo/design-docs/disaggregated-serving) treats that KV transfer as the bottleneck and points to RDMA or a similarly fast network for production multi-node setups. [Mooncake](https://github.com/kvcache-ai/Mooncake), used by Kimi, makes the same point from the serving side: cache placement, transfer, and request routing are now part of inference performance.
+
+The trend is toward more open networks and runtimes, not toward running one job across mismatched stacks. Ethernet efforts such as [Spectrum-X](https://www.nvidia.com/en-us/networking/spectrumx/), the [Ultra Ethernet Consortium](https://ultraethernet.org/ultra-ethernet-consortium-uec-launches-specification-1-0-transforming-ethernet-for-ai-and-hpc-at-scale/), [OCP ESUN](https://www.opencompute.org/blog/the-ocp-esun-10-specification-has-been-released), and AMD's [Helios](https://www.amd.com/en/blogs/2025/amd-helios-ai-rack-built-on-metas-2025-ocp-design.html) show growing momentum for open, fast Ethernet in AI clusters. That can reduce network lock-in and make mixed pools easier to run, but it does not yet make CUDA, ROCm, XLA, Neuron, serving engines, kernels, or KV-cache paths interchangeable.
+
+## Our take
+
+The rest of the report is neutral. Here is what we expect over the next 12 to 18 months:
+
+- **AMD stays inference-led.** AMD keeps winning inference deployments on price and memory, but its share of frontier training stays small through 2026, held back by ROCm and serving-engine maturity, not the hardware.
+- **Cloud chips stay locked in.** TPU and Trainium grow with the clouds that build them and their biggest customers, but neither becomes something a typical team can run anywhere else.
+- **Disaggregation becomes the norm.** Large-model inference increasingly splits prefill and decode onto separate pools, which makes moving the KV cache between them a core part of serving rather than a detail.
+- **Networking becomes vendor-neutral first.** Open Ethernet (UEC, Spectrum-X) makes the network portable across vendors well before the software stacks (CUDA, ROCm, XLA, Neuron) do.
+- **The scheduler war turns on neutrality.** NVIDIA owning both Slurm and Run:ai concentrates the scheduling layer around CUDA, and that concentration is exactly what mobilizes everyone else to fund a neutral control plane.
+- **Inference optimization goes agentic.** Choosing the serving engine, batch size, prefill/decode placement, routing, and caching is expensive hand-tuning today; as agents get better at this kind of search, the control plane starts doing it itself.
+
+??? info "Out of scope"
+
+ - **Custom silicon.** Controlled by individual hyperscalers or frontier labs; a supply signal, since large buyers can reserve or build capacity outside the public market, but not a generally adoptable path for most teams.
+ - **Chinese accelerators.** Huawei Ascend, Cambricon, and others may matter, especially in China, but comparable public data is limited and hard to verify from outside the region.
+ - **CPU-only workloads.** CPUs matter for agents, data processing, and application infrastructure, but this report focuses on accelerator paths for large-scale training and inference.
+ - **Sandboxes and agent runtimes.** Browser sandboxes, code-execution environments, and isolation layers matter for agent systems, but they are not accelerator paths.
+ - **FPGAs and experimental silicon.** This report focuses on mainstream AI accelerators used for large-scale training and inference.
diff --git a/mkdocs/overrides/main.html b/mkdocs/overrides/main.html
index 123b760be..7b44419ab 100644
--- a/mkdocs/overrides/main.html
+++ b/mkdocs/overrides/main.html
@@ -228,7 +228,7 @@
{% endblock %}
{% block announce %}
-Infrastructure orchestration is an agent skill
+The state of heterogeneous AI compute in 2026
{% endblock %}
{# Footer is rendered INSIDE .md-content (above, after the article) — NOT as a full-width sibling —
diff --git a/website/src/components/SiteBanner.tsx b/website/src/components/SiteBanner.tsx
index d092e8a4e..39e4fe3ab 100644
--- a/website/src/components/SiteBanner.tsx
+++ b/website/src/components/SiteBanner.tsx
@@ -3,8 +3,8 @@ import { BLOG_URL } from '../routes';
// Top announcement banner, mirroring the one on the MkDocs docs site. It sits above the top
// nav; the two stick to the top together (see .site-header). Update the copy/href here when
// the announcement changes.
-const BANNER_TEXT = 'Infrastructure orchestration is an agent skill';
-const BANNER_HREF = `${BLOG_URL}/agentic-orchestration/`;
+const BANNER_TEXT = 'The state of heterogeneous AI compute in 2026';
+const BANNER_HREF = `${BLOG_URL}/state-of-heterogeneous-compute-2026/`;
export function SiteBanner() {
return (
diff --git a/website/src/components/SiteNavigation.tsx b/website/src/components/SiteNavigation.tsx
index 28b99d46d..116c8cfda 100644
--- a/website/src/components/SiteNavigation.tsx
+++ b/website/src/components/SiteNavigation.tsx
@@ -14,12 +14,12 @@ const dstackGithubUrl = 'https://github.com/dstackai/dstack';
const externalIconAriaLabel = 'External link icon';
// Primary links in the desktop top navigation (plain same-origin MkDocs links). The blog
-// categories are listed individually (Case studies / Benchmarks / Blog) to mirror the docs
+// categories are listed individually (Case studies / Reports / Blog) to mirror the docs
// header tabs — no "Resources" dropdown.
const audienceNavItems: Array<{ label: string; href: string }> = [
{ label: 'Docs', href: DOCS_URL },
{ label: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { label: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { label: 'Reports', href: `${BLOG_URL}/reports/` },
{ label: 'Blog', href: BLOG_URL },
];
@@ -46,7 +46,7 @@ const productDropdownItems: ButtonDropdownProps.Items = [
const mobileNavigationItems: SideNavigationProps.Item[] = [
{ type: 'link', text: 'Docs', href: DOCS_URL },
{ type: 'link', text: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { type: 'link', text: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { type: 'link', text: 'Reports', href: `${BLOG_URL}/reports/` },
{ type: 'link', text: 'Blog', href: BLOG_URL },
{ type: 'link', text: 'GitHub', href: dstackGithubUrl, external: true, externalIconAriaLabel },
{
 +
+This report focuses on accelerator choices behind training and inference workloads: the main patterns, the evidence behind them, how readiness differs, and why orchestration and networking determine whether capacity can be used in practice.
+
+
+
+## Patterns
+
+Heterogeneous compute has two dimensions: how capacity is pooled, and where execution crosses hardware boundaries. Separate pools are operationally tractable; one training run or one inference request spanning unlike stacks requires much more validation. The patterns below are roughly ordered from most practical to most experimental.
+
+| Pattern | What it means |
+| :---- | :---- |
+| **Same stack, different generations** | Multiple generations of one vendor's stack: H100→GB300, MI300X→MI355X, TPU v5p→Ironwood, or the Trainium line. The runtime carries over, but memory, interconnect, availability, and tuning differ by generation. |
+| **Different stacks, separate workloads** | Training, fine-tuning, evaluation, batch inference, and online inference run on different accelerator stacks depending on supply, cost, and readiness. This is the most practical cross-stack pattern because each workload keeps its own runtime, image, kernels, and failure modes. |
+| **Requests routed across stacks** | One user-facing endpoint routes whole requests to complete deployments, each on its own accelerator stack. This uses mixed capacity without splitting a single inference; each deployment must still meet the same behavior, context, latency, and fallback requirements. |
+| **One training run across sites** | One training run spans clusters, regions, or datacenters, usually within the same accelerator and collective stack. This is capacity and fabric engineering, not generic portability; cross-vendor training remains frontier for most teams. |
+| **One inference request across stacks** | Prefill/decode split across unlike accelerator stacks is emerging. The phases stress compute, memory bandwidth, and networking differently, but public evidence is mostly research or partner-specific. Assume experimental until the exact serving path is demonstrated. |
+
+## Drivers
+
+Most accelerator decisions come down to a few practical questions: whether the team can get the right capacity, whether there is power to run it, and whether the software stack is ready for the workload.
+
+### Supply
+
+Accelerator choice is now part of capacity planning, not just performance tuning. The question is often how soon a team can get the right cluster shape, in the right region, with the right interconnect, quota, reservation terms, and price. Teams look at alternatives when the most familiar path means waiting too long, committing too much, or accepting capacity that does not fit the workload. The public signals below show supply strategy, not neutral performance proof.
+
+| Organization | Public figures | What it supports |
+| :---- | :---- | :---- |
+| **Anthropic** | Up to 1M [Google Cloud TPUs](https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services); up to 5 GW of additional [AWS capacity using Trainium](https://www.anthropic.com/news/anthropic-amazon-compute) | Frontier labs are willing to run across cloud-owned accelerator stacks when capacity and economics justify it. |
+| **OpenAI** | At least 10 GW of [NVIDIA systems](https://investor.nvidia.com/news/press-release-details/2025/OpenAI-and-NVIDIA-Announce-Strategic-Partnership-to-Deploy-10-Gigawatts-of-NVIDIA-Systems/default.aspx); 6 GW of [AMD GPUs](https://openai.com/index/openai-amd-strategic-partnership/) | Even the largest NVIDIA buyers are also pursuing merchant alternatives. |
+| **Meta** | Up to 6 GW of [AMD Instinct GPUs](https://ir.amd.com/news-events/press-releases/detail/1279/amd-and-meta-announce-expanded-strategic-partnership-to-deploy-6-gigawatts-of-amd-gpus) | Large buyers are adding non-NVIDIA merchant GPUs to their supply plans. |
+
+### Power
+
+At frontier scale, the limit is increasingly power, not chips. Getting accelerators also means getting power to run them, a grid connection, and cooling, each with its own multi-year lead time. That is why the deals above are sized in gigawatts.
+
+The racks are dense enough that liquid cooling is now required, not optional. [NVIDIA's GB300 NVL72](https://www.nvidia.com/en-us/data-center/gb300-nvl72/) draws about 135 kW; a full [Ironwood](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) pod is close to 10 MW; AMD's MI355X and coming Helios racks are in the same class.
+
+| Rack / chip | Power | Cooling |
+| :---- | :---- | :---- |
+| **NVIDIA GB300 NVL72** | ~135 kW per rack (~155 kW peak) | ~90% liquid; air not viable |
+| **TPU v7 (Ironwood)** | ~600 W per chip; ~10 MW per 9,216-chip pod | Liquid-cooled at pod scale |
+| **AMD MI355X / Helios** | High-density rack class | Liquid-cooled |
+
+So capacity planning is now also power planning, which favors buyers who control power and data-center space. It does not remove the software requirement: the stack still has to be ready.
+
+### Software
+
+An accelerator path is only relevant when the software stack is ready for the workload. The key checks:
+
+- **Baseline.** NVIDIA remains the reference path for kernels, collectives, containers, debugging, profiling, and operator experience.
+- **Runtime path.** AMD means ROCm/RCCL validation; TPUs mean XLA/JAX/PyTorch/XLA and Cloud TPU operations; Trainium means Neuron, compiler behavior, framework support, and AWS deployment paths.
+- **Serving path.** TensorRT-LLM, Triton Inference Server, Dynamo, vLLM, and SGLang matter because serving support is model-, backend-, and feature-specific. Gateways route across qualified backends; they do not make stacks interchangeable.
+- **Model path.** Attention kernels, quantization, precision, compiler behavior, and model-specific support can decide whether the workload is usable on a given accelerator.
+- **Specialized systems.** Groq and Cerebras are evaluated through supported models, latency, output speed, context support, deployment path, and price rather than as general-purpose accelerator pools.
+
+## Benchmarks
+
+This is not a ranking of accelerators. Benchmark evidence is useful when it says something concrete about the system, workload, precision, scale, and software path being evaluated.
+
+| Benchmark | What it shows | What it does not prove |
+| :---- | :---- | :---- |
+| **[MLPerf Training v6.0](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/)** | Standardized training submissions are broadening: 95 submitted systems, 13 accelerator types, 24 submitting organizations, and 60% multi-node systems. | That a vendor is ready for every training stack, model architecture, provider image, or cluster shape. |
+| **[MLPerf Inference v6.0](https://mlcommons.org/2026/04/mlperf-inference-v6-0-results/)** | Inference benchmarks are moving toward modern workloads, including new or updated datacenter tests and more multi-node submissions. | That service latency, cost, routing, KV cache behavior, or production failure modes will match the benchmark. |
+| **Vendor MLPerf writeups: [NVIDIA](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/), [AMD](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html)** | Configuration details and vendor interpretation, such as NVIDIA's Training v6.0 sweep or AMD's MI355X above 1M tokens/sec in Inference v6.0. | A neutral cross-vendor summary; the vendor chooses what to emphasize. |
+| **[SemiAnalysis InferenceX](https://inferencex.semianalysis.com/)** | Market and software movement as serving engines, kernels, quantization, and runtime choices improve, especially across NVIDIA and AMD GPU stacks. | A standardized benchmark suite or a complete market map across TPUs, Trainium, Groq, Cerebras, Tenstorrent, or every deployment path. |
+
+## Vendors
+
+Readiness turns theoretical supply into usable capacity: the question is not whether an accelerator exists or benchmarks well, but whether a team can use it for training or inference without making the accelerator choice the project. This section looks at each accelerator through three lenses: adoption profile, deployment flexibility, and readiness.
+
+### Adoption profiles
+
+Adoption profile describes where an accelerator is practical today.
+
+| Adoption profile | Meaning |
+| :---- | :---- |
+| **Broad adoption** | Broad software support, public availability, familiar operations, and minimal rewrites. |
+| **Early adopters** | More validation work is acceptable if the upside is large enough. |
+| **Cloud-committed** | One hyperscaler runtime is acceptable, with lower portability. |
+| **Specialized** | Supported models, latency, output speed, context, and price dominate. |
+
+!!! info "Frontier buyers"
+
+ For frontier buyers such as Anthropic, OpenAI, and Meta, supply is part of accelerator strategy, and the entry point differs by workload. Merchant alternatives like AMD come in through inference, while frontier training stays on NVIDIA or a deeply co-designed cloud stack (Anthropic has publicly committed to large-scale TPU and Trainium capacity to train and serve Claude, with the exact split inferred from those deals rather than disclosed).
+
+Deployment flexibility means whether the accelerator can be owned, rented, used through a specialized path, or used through one cloud stack.
+
+### Vendor categories
+
+| Category | Vendors | Why it is placed there |
+| :---- | :---- | :---- |
+| **Open market** | NVIDIA, AMD, Tenstorrent | Higher deployment flexibility: these accelerator paths are available outside one cloud owner. NVIDIA and AMD have broader public software and workload evidence; Tenstorrent remains earlier and more vendor-led. |
+| **Specialized inference** | Groq, Cerebras | Medium deployment flexibility: not cloud-owned, but narrower and optimized for supported inference models. Readiness depends on latency, output speed, context, price, and vendor stack fit rather than broad CUDA/ROCm/XLA/Neuron or vLLM/SGLang coverage. |
+| **Cloud-owned** | Google TPUs, AWS Trainium | Lower deployment flexibility: these accelerator paths are rented through the cloud that owns the chip and runtime. The trade-off is portability, not whether the stack is useful; both can be strong when the cloud commitment is acceptable. |
+
+### Vendor readiness
+
+| Vendor | Fits | Readiness signal | Main constraint |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA** | Direct accelerator use across training, fine-tuning, batch inference, and self-hosted online inference in public clouds and private clusters. | The depth of the [CUDA](https://docs.nvidia.com/cuda/) ecosystem: kernels, [NCCL](https://docs.nvidia.com/deeplearning/nccl/), [TensorRT-LLM](https://docs.nvidia.com/tensorrt-llm/), [Triton](https://docs.nvidia.com/deeplearning/triton-inference-server/index.html), [Dynamo](https://www.nvidia.com/en-us/ai/dynamo/), and the broadest tooling and provider support, plus the only clean sweep in [MLPerf Training v6.0](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/) (the lone platform to submit on every test). | Cost and access. NVIDIA is premium-priced and supply is contended, so commitment terms and fabric availability often gate a team more than performance does. |
+| **AMD** | Merchant GPU path outside an NVIDIA-only plan, with validation on the exact workload instead of assuming CUDA compatibility. | The strongest non-NVIDIA case. MI355X cleared 1M tokens/sec in [Inference v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html) with 288GB HBM3e (50% over B200); its first multi-node [Training v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-training-6-0-results.html) submission came within ~6% of B200 on the LLM tests, on [ROCm](https://rocm.docs.amd.com/en/latest/index.html)/[RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html). | Software, not silicon. ROCm performance depends on the serving engine and version (on several current open-model benchmarks SGLang has led vLLM, though leadership shifts by model and release); training trails inference; and cloud availability, though growing, is narrower than NVIDIA's. |
+| **Tenstorrent** | Early adopters evaluating a direct accelerator path that is not tied to CUDA or a hyperscaler-owned runtime. | The [Galaxy Blackhole launch](https://tenstorrent.com/en/newsroom/tenstorrent-enables-ai-at-scale-with-industry-leading-performance), where Tenstorrent reports deployed superclusters, LLM and video-generation workload claims, and a stack built around TT-Metal, TT-NN, TT-Forge, and TT-MLIR. | Software maturity and access. Inference runs through Tenstorrent's [vLLM fork](https://github.com/tenstorrent/vllm) on a validated, per-gen model list (not day-0), with no established training or disaggregated-serving path. Capacity is mostly direct purchase, not in clouds. Hardware is real and the stack is open; treat the software as early. |
+| **TPU** | Google Cloud-anchored workloads that can build around XLA, JAX, PyTorch/XLA, and Cloud TPU infrastructure. | [Ironwood (TPU v7)](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) is GA, and large-scale production use (e.g. Anthropic) is the main readiness signal. | Access and lock-in. Capacity is quota-gated and still ramping externally; GCP-only; model support is XLA/JAX-first, so day-0 coverage can lag; and there's little neutral benchmark evidence for Ironwood. The economics can still win on TCO. |
+| **Trainium** | AWS-committed workloads that can build around [Neuron](https://awsdocs-neuron.readthedocs-hosted.com/) rather than treating it as a drop-in GPU replacement. | [Trainium3 UltraServers](https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-ec2-trn3-ultraservers/) are GA as system-scale infrastructure, and Anthropic runs production training on Trainium, the main readiness signal. | Software and evidence. Neuron's compiler/runtime is the gating gap versus CUDA, and with no neutral benchmark (AWS doesn't submit to MLPerf) readiness rests on AWS's numbers and Anthropic's use. AWS-only, with day-0 model coverage tied to Neuron. |
+| **Groq and Cerebras** | Specialized cases for supported inference models, where latency, output speed, context, and price matter more than general accelerator access. | Service-level results (throughput, time-to-first-token, context), not general benchmarks. Cerebras publishes current numbers across [Gemma 4](https://www.cerebras.ai/blog/gemma-4-on-cerebras-the-fastest-inference-is-now-multimodal) and GPT-OSS 120B. | Inference-only, with curated (not day-0) model support, so you're betting on the vendor's roadmap. Those bets now diverge: Groq is entangled with NVIDIA after its [December 2025 deal](https://www.networkworld.com/article/4112131/nvidia-licenses-groqs-inferencing-chip-tech-and-hires-its-leaders.html); Cerebras stays independent (recent [IPO](https://www.theregister.com/ai-ml/2026/05/15/cerebras-wafer-scale-ai-bet-delivers-blockbuster-ipo/5240821)). |
+
+## Orchestration
+
+Orchestration is more than a scheduler queue. It lets teams describe training jobs, batch jobs, and services (images, resources, placement) once, then handles the operational work of running them: provisioning, scaling, retries, and recovery. What it cannot remove is compatibility: CUDA, ROCm, XLA, Neuron, collective libraries, serving engines, and kernels are not interchangeable, so the control plane matches each workload to capacity that can actually run it.
+
+| Stack | Role and trade-off |
+| :---- | :---- |
+| **Kubernetes** | Strong substrate for containers, services, operators, and internal platforms. For AI, it often requires stitching together device plugins, vendor GPU operators, Dynamic Resource Allocation, Kueue or Volcano, Kubeflow, KubeRay, autoscaling, and serving layers. Kubernetes-native multi-cluster tooling helps when capacity is already Kubernetes, but it still leaves accelerator discovery, quotas, procurement, runtime images, and cross-cloud placement as platform work. |
+| **Slurm** | Strong for large batch clusters, queueing, accounting, policy, and topology-aware placement. The limits are cloud-native and container-native workflows: real deployments often depend on local modules, queues, prolog/epilog scripts, plugins, and launch conventions. NVIDIA's SchedMD acquisition also makes Slurm vendor independence something teams should watch. |
+| **Emerging** | AI-native control planes such as `dstack` and SkyPilot focus on making scattered accelerator capacity usable through higher-level workload definitions for training jobs, batch jobs, and services. They reduce the glue work created by fragmented clouds, clusters, accelerators, runtimes, and sites, which otherwise falls to platform teams. They still depend on each accelerator stack and serving runtime for kernels, images, collectives, routing, and performance. |
+
+**Distributed inference.** Runtimes such as SGLang, Dynamo, vLLM, Mooncake, and NIXL handle routing, batching, prefill/decode behavior, and KV cache movement; orchestration deploys and runs those setups across compatible capacity.
+
+**RL post-training.** One job runs a training stack (FSDP/Megatron) and a generation stack (vLLM/SGLang) at once, with the trainer pushing fresh weights to the rollout workers every step. [Ray](https://github.com/ray-project/ray) has become the common foundation here: it co-schedules the trainer and rollout roles, colocated or split across pools, and keeps the weight sync from stalling each step.
+
+!!! info "Vendor independence"
+ The orchestration and control-plane layer should not quietly become another accelerator dependency. NVIDIA acquired [Run:ai](https://blogs.nvidia.com/blog/runai/), a Kubernetes-based workload management platform, and [SchedMD](https://blogs.nvidia.com/blog/nvidia-acquires-schedmd/), the leading developer of Slurm. NVIDIA says Slurm will remain open-source and vendor-neutral, and its Run:ai messaging emphasizes choice and flexibility. Teams may still trust those projects, but heterogeneous compute makes vendor independence a practical requirement for the scheduler and control plane.
+
+## Networking
+
+For training, the practical case is usually one accelerator stack spread across sites, regions, or generations. The job still depends on a matching collective-communication library: [NCCL](https://docs.nvidia.com/deeplearning/nccl/) for NVIDIA, [RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html) for AMD, and cloud-specific fabrics for TPUs and Trainium. Full-system results such as [MLPerf Training](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/) help confirm that a single-stack cluster scales; they do not make cross-vendor training portable.
+
+The key difference is the scale-up domain: how many accelerators sit in one fast, tightly connected pool before traffic has to cross a slower network.
+
+| Stack | Scale-up domain | Per-accelerator bandwidth | Interconnect |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA Vera Rubin NVL72** | 72 GPUs (one rack, 2H 2026) | 3.6 TB/s per GPU | NVLink 6, all-to-all |
+| **AMD Helios (MI455X)** | 72 GPUs (one rack, 2H 2026) | ~0.9 TB/s per GPU | UALink over Ethernet |
+| **TPU v7 (Ironwood)** | up to 9,216 chips (pod) | ~1.2 TB/s per chip | ICI 3D torus + optical switching |
+| **AWS Trainium3** | 144 chips (Trn3 UltraServer) | ~2 TB/s per chip | NeuronLink all-to-all |
+
+GPU racks and Trainium keep their fast domains in the dozens to ~150 accelerators; only TPU's torus reaches the thousands. The two GPU racks are about even on total bandwidth (~260 TB/s), but NVIDIA's per-GPU link is roughly 4x AMD's, which matters for training. None of this makes the stacks interchangeable, and a 9,216-chip pod only helps if the model can actually use it.
+
+For inference, the practical case is disaggregated serving within a compatible stack: prefill workers, decode workers, routing, and a path to move the KV cache. NVIDIA's [Dynamo disaggregated serving](https://docs.nvidia.com/dynamo/design-docs/disaggregated-serving) treats that KV transfer as the bottleneck and points to RDMA or a similarly fast network for production multi-node setups. [Mooncake](https://github.com/kvcache-ai/Mooncake), used by Kimi, makes the same point from the serving side: cache placement, transfer, and request routing are now part of inference performance.
+
+The trend is toward more open networks and runtimes, not toward running one job across mismatched stacks. Ethernet efforts such as [Spectrum-X](https://www.nvidia.com/en-us/networking/spectrumx/), the [Ultra Ethernet Consortium](https://ultraethernet.org/ultra-ethernet-consortium-uec-launches-specification-1-0-transforming-ethernet-for-ai-and-hpc-at-scale/), [OCP ESUN](https://www.opencompute.org/blog/the-ocp-esun-10-specification-has-been-released), and AMD's [Helios](https://www.amd.com/en/blogs/2025/amd-helios-ai-rack-built-on-metas-2025-ocp-design.html) show growing momentum for open, fast Ethernet in AI clusters. That can reduce network lock-in and make mixed pools easier to run, but it does not yet make CUDA, ROCm, XLA, Neuron, serving engines, kernels, or KV-cache paths interchangeable.
+
+## Our take
+
+The rest of the report is neutral. Here is what we expect over the next 12 to 18 months:
+
+- **AMD stays inference-led.** AMD keeps winning inference deployments on price and memory, but its share of frontier training stays small through 2026, held back by ROCm and serving-engine maturity, not the hardware.
+- **Cloud chips stay locked in.** TPU and Trainium grow with the clouds that build them and their biggest customers, but neither becomes something a typical team can run anywhere else.
+- **Disaggregation becomes the norm.** Large-model inference increasingly splits prefill and decode onto separate pools, which makes moving the KV cache between them a core part of serving rather than a detail.
+- **Networking becomes vendor-neutral first.** Open Ethernet (UEC, Spectrum-X) makes the network portable across vendors well before the software stacks (CUDA, ROCm, XLA, Neuron) do.
+- **The scheduler war turns on neutrality.** NVIDIA owning both Slurm and Run:ai concentrates the scheduling layer around CUDA, and that concentration is exactly what mobilizes everyone else to fund a neutral control plane.
+- **Inference optimization goes agentic.** Choosing the serving engine, batch size, prefill/decode placement, routing, and caching is expensive hand-tuning today; as agents get better at this kind of search, the control plane starts doing it itself.
+
+??? info "Out of scope"
+
+ - **Custom silicon.** Controlled by individual hyperscalers or frontier labs; a supply signal, since large buyers can reserve or build capacity outside the public market, but not a generally adoptable path for most teams.
+ - **Chinese accelerators.** Huawei Ascend, Cambricon, and others may matter, especially in China, but comparable public data is limited and hard to verify from outside the region.
+ - **CPU-only workloads.** CPUs matter for agents, data processing, and application infrastructure, but this report focuses on accelerator paths for large-scale training and inference.
+ - **Sandboxes and agent runtimes.** Browser sandboxes, code-execution environments, and isolation layers matter for agent systems, but they are not accelerator paths.
+ - **FPGAs and experimental silicon.** This report focuses on mainstream AI accelerators used for large-scale training and inference.
diff --git a/mkdocs/overrides/main.html b/mkdocs/overrides/main.html
index 123b760be..7b44419ab 100644
--- a/mkdocs/overrides/main.html
+++ b/mkdocs/overrides/main.html
@@ -228,7 +228,7 @@
{% endblock %}
{% block announce %}
-Infrastructure orchestration is an agent skill
+The state of heterogeneous AI compute in 2026
{% endblock %}
{# Footer is rendered INSIDE .md-content (above, after the article) — NOT as a full-width sibling —
diff --git a/website/src/components/SiteBanner.tsx b/website/src/components/SiteBanner.tsx
index d092e8a4e..39e4fe3ab 100644
--- a/website/src/components/SiteBanner.tsx
+++ b/website/src/components/SiteBanner.tsx
@@ -3,8 +3,8 @@ import { BLOG_URL } from '../routes';
// Top announcement banner, mirroring the one on the MkDocs docs site. It sits above the top
// nav; the two stick to the top together (see .site-header). Update the copy/href here when
// the announcement changes.
-const BANNER_TEXT = 'Infrastructure orchestration is an agent skill';
-const BANNER_HREF = `${BLOG_URL}/agentic-orchestration/`;
+const BANNER_TEXT = 'The state of heterogeneous AI compute in 2026';
+const BANNER_HREF = `${BLOG_URL}/state-of-heterogeneous-compute-2026/`;
export function SiteBanner() {
return (
diff --git a/website/src/components/SiteNavigation.tsx b/website/src/components/SiteNavigation.tsx
index 28b99d46d..116c8cfda 100644
--- a/website/src/components/SiteNavigation.tsx
+++ b/website/src/components/SiteNavigation.tsx
@@ -14,12 +14,12 @@ const dstackGithubUrl = 'https://github.com/dstackai/dstack';
const externalIconAriaLabel = 'External link icon';
// Primary links in the desktop top navigation (plain same-origin MkDocs links). The blog
-// categories are listed individually (Case studies / Benchmarks / Blog) to mirror the docs
+// categories are listed individually (Case studies / Reports / Blog) to mirror the docs
// header tabs — no "Resources" dropdown.
const audienceNavItems: Array<{ label: string; href: string }> = [
{ label: 'Docs', href: DOCS_URL },
{ label: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { label: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { label: 'Reports', href: `${BLOG_URL}/reports/` },
{ label: 'Blog', href: BLOG_URL },
];
@@ -46,7 +46,7 @@ const productDropdownItems: ButtonDropdownProps.Items = [
const mobileNavigationItems: SideNavigationProps.Item[] = [
{ type: 'link', text: 'Docs', href: DOCS_URL },
{ type: 'link', text: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { type: 'link', text: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { type: 'link', text: 'Reports', href: `${BLOG_URL}/reports/` },
{ type: 'link', text: 'Blog', href: BLOG_URL },
{ type: 'link', text: 'GitHub', href: dstackGithubUrl, external: true, externalIconAriaLabel },
{
+
+This report focuses on accelerator choices behind training and inference workloads: the main patterns, the evidence behind them, how readiness differs, and why orchestration and networking determine whether capacity can be used in practice.
+
+
+
+## Patterns
+
+Heterogeneous compute has two dimensions: how capacity is pooled, and where execution crosses hardware boundaries. Separate pools are operationally tractable; one training run or one inference request spanning unlike stacks requires much more validation. The patterns below are roughly ordered from most practical to most experimental.
+
+| Pattern | What it means |
+| :---- | :---- |
+| **Same stack, different generations** | Multiple generations of one vendor's stack: H100→GB300, MI300X→MI355X, TPU v5p→Ironwood, or the Trainium line. The runtime carries over, but memory, interconnect, availability, and tuning differ by generation. |
+| **Different stacks, separate workloads** | Training, fine-tuning, evaluation, batch inference, and online inference run on different accelerator stacks depending on supply, cost, and readiness. This is the most practical cross-stack pattern because each workload keeps its own runtime, image, kernels, and failure modes. |
+| **Requests routed across stacks** | One user-facing endpoint routes whole requests to complete deployments, each on its own accelerator stack. This uses mixed capacity without splitting a single inference; each deployment must still meet the same behavior, context, latency, and fallback requirements. |
+| **One training run across sites** | One training run spans clusters, regions, or datacenters, usually within the same accelerator and collective stack. This is capacity and fabric engineering, not generic portability; cross-vendor training remains frontier for most teams. |
+| **One inference request across stacks** | Prefill/decode split across unlike accelerator stacks is emerging. The phases stress compute, memory bandwidth, and networking differently, but public evidence is mostly research or partner-specific. Assume experimental until the exact serving path is demonstrated. |
+
+## Drivers
+
+Most accelerator decisions come down to a few practical questions: whether the team can get the right capacity, whether there is power to run it, and whether the software stack is ready for the workload.
+
+### Supply
+
+Accelerator choice is now part of capacity planning, not just performance tuning. The question is often how soon a team can get the right cluster shape, in the right region, with the right interconnect, quota, reservation terms, and price. Teams look at alternatives when the most familiar path means waiting too long, committing too much, or accepting capacity that does not fit the workload. The public signals below show supply strategy, not neutral performance proof.
+
+| Organization | Public figures | What it supports |
+| :---- | :---- | :---- |
+| **Anthropic** | Up to 1M [Google Cloud TPUs](https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services); up to 5 GW of additional [AWS capacity using Trainium](https://www.anthropic.com/news/anthropic-amazon-compute) | Frontier labs are willing to run across cloud-owned accelerator stacks when capacity and economics justify it. |
+| **OpenAI** | At least 10 GW of [NVIDIA systems](https://investor.nvidia.com/news/press-release-details/2025/OpenAI-and-NVIDIA-Announce-Strategic-Partnership-to-Deploy-10-Gigawatts-of-NVIDIA-Systems/default.aspx); 6 GW of [AMD GPUs](https://openai.com/index/openai-amd-strategic-partnership/) | Even the largest NVIDIA buyers are also pursuing merchant alternatives. |
+| **Meta** | Up to 6 GW of [AMD Instinct GPUs](https://ir.amd.com/news-events/press-releases/detail/1279/amd-and-meta-announce-expanded-strategic-partnership-to-deploy-6-gigawatts-of-amd-gpus) | Large buyers are adding non-NVIDIA merchant GPUs to their supply plans. |
+
+### Power
+
+At frontier scale, the limit is increasingly power, not chips. Getting accelerators also means getting power to run them, a grid connection, and cooling, each with its own multi-year lead time. That is why the deals above are sized in gigawatts.
+
+The racks are dense enough that liquid cooling is now required, not optional. [NVIDIA's GB300 NVL72](https://www.nvidia.com/en-us/data-center/gb300-nvl72/) draws about 135 kW; a full [Ironwood](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) pod is close to 10 MW; AMD's MI355X and coming Helios racks are in the same class.
+
+| Rack / chip | Power | Cooling |
+| :---- | :---- | :---- |
+| **NVIDIA GB300 NVL72** | ~135 kW per rack (~155 kW peak) | ~90% liquid; air not viable |
+| **TPU v7 (Ironwood)** | ~600 W per chip; ~10 MW per 9,216-chip pod | Liquid-cooled at pod scale |
+| **AMD MI355X / Helios** | High-density rack class | Liquid-cooled |
+
+So capacity planning is now also power planning, which favors buyers who control power and data-center space. It does not remove the software requirement: the stack still has to be ready.
+
+### Software
+
+An accelerator path is only relevant when the software stack is ready for the workload. The key checks:
+
+- **Baseline.** NVIDIA remains the reference path for kernels, collectives, containers, debugging, profiling, and operator experience.
+- **Runtime path.** AMD means ROCm/RCCL validation; TPUs mean XLA/JAX/PyTorch/XLA and Cloud TPU operations; Trainium means Neuron, compiler behavior, framework support, and AWS deployment paths.
+- **Serving path.** TensorRT-LLM, Triton Inference Server, Dynamo, vLLM, and SGLang matter because serving support is model-, backend-, and feature-specific. Gateways route across qualified backends; they do not make stacks interchangeable.
+- **Model path.** Attention kernels, quantization, precision, compiler behavior, and model-specific support can decide whether the workload is usable on a given accelerator.
+- **Specialized systems.** Groq and Cerebras are evaluated through supported models, latency, output speed, context support, deployment path, and price rather than as general-purpose accelerator pools.
+
+## Benchmarks
+
+This is not a ranking of accelerators. Benchmark evidence is useful when it says something concrete about the system, workload, precision, scale, and software path being evaluated.
+
+| Benchmark | What it shows | What it does not prove |
+| :---- | :---- | :---- |
+| **[MLPerf Training v6.0](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/)** | Standardized training submissions are broadening: 95 submitted systems, 13 accelerator types, 24 submitting organizations, and 60% multi-node systems. | That a vendor is ready for every training stack, model architecture, provider image, or cluster shape. |
+| **[MLPerf Inference v6.0](https://mlcommons.org/2026/04/mlperf-inference-v6-0-results/)** | Inference benchmarks are moving toward modern workloads, including new or updated datacenter tests and more multi-node submissions. | That service latency, cost, routing, KV cache behavior, or production failure modes will match the benchmark. |
+| **Vendor MLPerf writeups: [NVIDIA](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/), [AMD](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html)** | Configuration details and vendor interpretation, such as NVIDIA's Training v6.0 sweep or AMD's MI355X above 1M tokens/sec in Inference v6.0. | A neutral cross-vendor summary; the vendor chooses what to emphasize. |
+| **[SemiAnalysis InferenceX](https://inferencex.semianalysis.com/)** | Market and software movement as serving engines, kernels, quantization, and runtime choices improve, especially across NVIDIA and AMD GPU stacks. | A standardized benchmark suite or a complete market map across TPUs, Trainium, Groq, Cerebras, Tenstorrent, or every deployment path. |
+
+## Vendors
+
+Readiness turns theoretical supply into usable capacity: the question is not whether an accelerator exists or benchmarks well, but whether a team can use it for training or inference without making the accelerator choice the project. This section looks at each accelerator through three lenses: adoption profile, deployment flexibility, and readiness.
+
+### Adoption profiles
+
+Adoption profile describes where an accelerator is practical today.
+
+| Adoption profile | Meaning |
+| :---- | :---- |
+| **Broad adoption** | Broad software support, public availability, familiar operations, and minimal rewrites. |
+| **Early adopters** | More validation work is acceptable if the upside is large enough. |
+| **Cloud-committed** | One hyperscaler runtime is acceptable, with lower portability. |
+| **Specialized** | Supported models, latency, output speed, context, and price dominate. |
+
+!!! info "Frontier buyers"
+
+ For frontier buyers such as Anthropic, OpenAI, and Meta, supply is part of accelerator strategy, and the entry point differs by workload. Merchant alternatives like AMD come in through inference, while frontier training stays on NVIDIA or a deeply co-designed cloud stack (Anthropic has publicly committed to large-scale TPU and Trainium capacity to train and serve Claude, with the exact split inferred from those deals rather than disclosed).
+
+Deployment flexibility means whether the accelerator can be owned, rented, used through a specialized path, or used through one cloud stack.
+
+### Vendor categories
+
+| Category | Vendors | Why it is placed there |
+| :---- | :---- | :---- |
+| **Open market** | NVIDIA, AMD, Tenstorrent | Higher deployment flexibility: these accelerator paths are available outside one cloud owner. NVIDIA and AMD have broader public software and workload evidence; Tenstorrent remains earlier and more vendor-led. |
+| **Specialized inference** | Groq, Cerebras | Medium deployment flexibility: not cloud-owned, but narrower and optimized for supported inference models. Readiness depends on latency, output speed, context, price, and vendor stack fit rather than broad CUDA/ROCm/XLA/Neuron or vLLM/SGLang coverage. |
+| **Cloud-owned** | Google TPUs, AWS Trainium | Lower deployment flexibility: these accelerator paths are rented through the cloud that owns the chip and runtime. The trade-off is portability, not whether the stack is useful; both can be strong when the cloud commitment is acceptable. |
+
+### Vendor readiness
+
+| Vendor | Fits | Readiness signal | Main constraint |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA** | Direct accelerator use across training, fine-tuning, batch inference, and self-hosted online inference in public clouds and private clusters. | The depth of the [CUDA](https://docs.nvidia.com/cuda/) ecosystem: kernels, [NCCL](https://docs.nvidia.com/deeplearning/nccl/), [TensorRT-LLM](https://docs.nvidia.com/tensorrt-llm/), [Triton](https://docs.nvidia.com/deeplearning/triton-inference-server/index.html), [Dynamo](https://www.nvidia.com/en-us/ai/dynamo/), and the broadest tooling and provider support, plus the only clean sweep in [MLPerf Training v6.0](https://blogs.nvidia.com/blog/blackwell-mlperf-training-6-0/) (the lone platform to submit on every test). | Cost and access. NVIDIA is premium-priced and supply is contended, so commitment terms and fabric availability often gate a team more than performance does. |
+| **AMD** | Merchant GPU path outside an NVIDIA-only plan, with validation on the exact workload instead of assuming CUDA compatibility. | The strongest non-NVIDIA case. MI355X cleared 1M tokens/sec in [Inference v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-inference-6-0-results.html) with 288GB HBM3e (50% over B200); its first multi-node [Training v6.0](https://www.amd.com/en/blogs/2026/amd-delivers-breakthrough-mlperf-training-6-0-results.html) submission came within ~6% of B200 on the LLM tests, on [ROCm](https://rocm.docs.amd.com/en/latest/index.html)/[RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html). | Software, not silicon. ROCm performance depends on the serving engine and version (on several current open-model benchmarks SGLang has led vLLM, though leadership shifts by model and release); training trails inference; and cloud availability, though growing, is narrower than NVIDIA's. |
+| **Tenstorrent** | Early adopters evaluating a direct accelerator path that is not tied to CUDA or a hyperscaler-owned runtime. | The [Galaxy Blackhole launch](https://tenstorrent.com/en/newsroom/tenstorrent-enables-ai-at-scale-with-industry-leading-performance), where Tenstorrent reports deployed superclusters, LLM and video-generation workload claims, and a stack built around TT-Metal, TT-NN, TT-Forge, and TT-MLIR. | Software maturity and access. Inference runs through Tenstorrent's [vLLM fork](https://github.com/tenstorrent/vllm) on a validated, per-gen model list (not day-0), with no established training or disaggregated-serving path. Capacity is mostly direct purchase, not in clouds. Hardware is real and the stack is open; treat the software as early. |
+| **TPU** | Google Cloud-anchored workloads that can build around XLA, JAX, PyTorch/XLA, and Cloud TPU infrastructure. | [Ironwood (TPU v7)](https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads) is GA, and large-scale production use (e.g. Anthropic) is the main readiness signal. | Access and lock-in. Capacity is quota-gated and still ramping externally; GCP-only; model support is XLA/JAX-first, so day-0 coverage can lag; and there's little neutral benchmark evidence for Ironwood. The economics can still win on TCO. |
+| **Trainium** | AWS-committed workloads that can build around [Neuron](https://awsdocs-neuron.readthedocs-hosted.com/) rather than treating it as a drop-in GPU replacement. | [Trainium3 UltraServers](https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-ec2-trn3-ultraservers/) are GA as system-scale infrastructure, and Anthropic runs production training on Trainium, the main readiness signal. | Software and evidence. Neuron's compiler/runtime is the gating gap versus CUDA, and with no neutral benchmark (AWS doesn't submit to MLPerf) readiness rests on AWS's numbers and Anthropic's use. AWS-only, with day-0 model coverage tied to Neuron. |
+| **Groq and Cerebras** | Specialized cases for supported inference models, where latency, output speed, context, and price matter more than general accelerator access. | Service-level results (throughput, time-to-first-token, context), not general benchmarks. Cerebras publishes current numbers across [Gemma 4](https://www.cerebras.ai/blog/gemma-4-on-cerebras-the-fastest-inference-is-now-multimodal) and GPT-OSS 120B. | Inference-only, with curated (not day-0) model support, so you're betting on the vendor's roadmap. Those bets now diverge: Groq is entangled with NVIDIA after its [December 2025 deal](https://www.networkworld.com/article/4112131/nvidia-licenses-groqs-inferencing-chip-tech-and-hires-its-leaders.html); Cerebras stays independent (recent [IPO](https://www.theregister.com/ai-ml/2026/05/15/cerebras-wafer-scale-ai-bet-delivers-blockbuster-ipo/5240821)). |
+
+## Orchestration
+
+Orchestration is more than a scheduler queue. It lets teams describe training jobs, batch jobs, and services (images, resources, placement) once, then handles the operational work of running them: provisioning, scaling, retries, and recovery. What it cannot remove is compatibility: CUDA, ROCm, XLA, Neuron, collective libraries, serving engines, and kernels are not interchangeable, so the control plane matches each workload to capacity that can actually run it.
+
+| Stack | Role and trade-off |
+| :---- | :---- |
+| **Kubernetes** | Strong substrate for containers, services, operators, and internal platforms. For AI, it often requires stitching together device plugins, vendor GPU operators, Dynamic Resource Allocation, Kueue or Volcano, Kubeflow, KubeRay, autoscaling, and serving layers. Kubernetes-native multi-cluster tooling helps when capacity is already Kubernetes, but it still leaves accelerator discovery, quotas, procurement, runtime images, and cross-cloud placement as platform work. |
+| **Slurm** | Strong for large batch clusters, queueing, accounting, policy, and topology-aware placement. The limits are cloud-native and container-native workflows: real deployments often depend on local modules, queues, prolog/epilog scripts, plugins, and launch conventions. NVIDIA's SchedMD acquisition also makes Slurm vendor independence something teams should watch. |
+| **Emerging** | AI-native control planes such as `dstack` and SkyPilot focus on making scattered accelerator capacity usable through higher-level workload definitions for training jobs, batch jobs, and services. They reduce the glue work created by fragmented clouds, clusters, accelerators, runtimes, and sites, which otherwise falls to platform teams. They still depend on each accelerator stack and serving runtime for kernels, images, collectives, routing, and performance. |
+
+**Distributed inference.** Runtimes such as SGLang, Dynamo, vLLM, Mooncake, and NIXL handle routing, batching, prefill/decode behavior, and KV cache movement; orchestration deploys and runs those setups across compatible capacity.
+
+**RL post-training.** One job runs a training stack (FSDP/Megatron) and a generation stack (vLLM/SGLang) at once, with the trainer pushing fresh weights to the rollout workers every step. [Ray](https://github.com/ray-project/ray) has become the common foundation here: it co-schedules the trainer and rollout roles, colocated or split across pools, and keeps the weight sync from stalling each step.
+
+!!! info "Vendor independence"
+ The orchestration and control-plane layer should not quietly become another accelerator dependency. NVIDIA acquired [Run:ai](https://blogs.nvidia.com/blog/runai/), a Kubernetes-based workload management platform, and [SchedMD](https://blogs.nvidia.com/blog/nvidia-acquires-schedmd/), the leading developer of Slurm. NVIDIA says Slurm will remain open-source and vendor-neutral, and its Run:ai messaging emphasizes choice and flexibility. Teams may still trust those projects, but heterogeneous compute makes vendor independence a practical requirement for the scheduler and control plane.
+
+## Networking
+
+For training, the practical case is usually one accelerator stack spread across sites, regions, or generations. The job still depends on a matching collective-communication library: [NCCL](https://docs.nvidia.com/deeplearning/nccl/) for NVIDIA, [RCCL](https://rocm.docs.amd.com/projects/rccl/en/latest/index.html) for AMD, and cloud-specific fabrics for TPUs and Trainium. Full-system results such as [MLPerf Training](https://mlcommons.org/2026/06/mlperf-training-v6-0-results/) help confirm that a single-stack cluster scales; they do not make cross-vendor training portable.
+
+The key difference is the scale-up domain: how many accelerators sit in one fast, tightly connected pool before traffic has to cross a slower network.
+
+| Stack | Scale-up domain | Per-accelerator bandwidth | Interconnect |
+| :---- | :---- | :---- | :---- |
+| **NVIDIA Vera Rubin NVL72** | 72 GPUs (one rack, 2H 2026) | 3.6 TB/s per GPU | NVLink 6, all-to-all |
+| **AMD Helios (MI455X)** | 72 GPUs (one rack, 2H 2026) | ~0.9 TB/s per GPU | UALink over Ethernet |
+| **TPU v7 (Ironwood)** | up to 9,216 chips (pod) | ~1.2 TB/s per chip | ICI 3D torus + optical switching |
+| **AWS Trainium3** | 144 chips (Trn3 UltraServer) | ~2 TB/s per chip | NeuronLink all-to-all |
+
+GPU racks and Trainium keep their fast domains in the dozens to ~150 accelerators; only TPU's torus reaches the thousands. The two GPU racks are about even on total bandwidth (~260 TB/s), but NVIDIA's per-GPU link is roughly 4x AMD's, which matters for training. None of this makes the stacks interchangeable, and a 9,216-chip pod only helps if the model can actually use it.
+
+For inference, the practical case is disaggregated serving within a compatible stack: prefill workers, decode workers, routing, and a path to move the KV cache. NVIDIA's [Dynamo disaggregated serving](https://docs.nvidia.com/dynamo/design-docs/disaggregated-serving) treats that KV transfer as the bottleneck and points to RDMA or a similarly fast network for production multi-node setups. [Mooncake](https://github.com/kvcache-ai/Mooncake), used by Kimi, makes the same point from the serving side: cache placement, transfer, and request routing are now part of inference performance.
+
+The trend is toward more open networks and runtimes, not toward running one job across mismatched stacks. Ethernet efforts such as [Spectrum-X](https://www.nvidia.com/en-us/networking/spectrumx/), the [Ultra Ethernet Consortium](https://ultraethernet.org/ultra-ethernet-consortium-uec-launches-specification-1-0-transforming-ethernet-for-ai-and-hpc-at-scale/), [OCP ESUN](https://www.opencompute.org/blog/the-ocp-esun-10-specification-has-been-released), and AMD's [Helios](https://www.amd.com/en/blogs/2025/amd-helios-ai-rack-built-on-metas-2025-ocp-design.html) show growing momentum for open, fast Ethernet in AI clusters. That can reduce network lock-in and make mixed pools easier to run, but it does not yet make CUDA, ROCm, XLA, Neuron, serving engines, kernels, or KV-cache paths interchangeable.
+
+## Our take
+
+The rest of the report is neutral. Here is what we expect over the next 12 to 18 months:
+
+- **AMD stays inference-led.** AMD keeps winning inference deployments on price and memory, but its share of frontier training stays small through 2026, held back by ROCm and serving-engine maturity, not the hardware.
+- **Cloud chips stay locked in.** TPU and Trainium grow with the clouds that build them and their biggest customers, but neither becomes something a typical team can run anywhere else.
+- **Disaggregation becomes the norm.** Large-model inference increasingly splits prefill and decode onto separate pools, which makes moving the KV cache between them a core part of serving rather than a detail.
+- **Networking becomes vendor-neutral first.** Open Ethernet (UEC, Spectrum-X) makes the network portable across vendors well before the software stacks (CUDA, ROCm, XLA, Neuron) do.
+- **The scheduler war turns on neutrality.** NVIDIA owning both Slurm and Run:ai concentrates the scheduling layer around CUDA, and that concentration is exactly what mobilizes everyone else to fund a neutral control plane.
+- **Inference optimization goes agentic.** Choosing the serving engine, batch size, prefill/decode placement, routing, and caching is expensive hand-tuning today; as agents get better at this kind of search, the control plane starts doing it itself.
+
+??? info "Out of scope"
+
+ - **Custom silicon.** Controlled by individual hyperscalers or frontier labs; a supply signal, since large buyers can reserve or build capacity outside the public market, but not a generally adoptable path for most teams.
+ - **Chinese accelerators.** Huawei Ascend, Cambricon, and others may matter, especially in China, but comparable public data is limited and hard to verify from outside the region.
+ - **CPU-only workloads.** CPUs matter for agents, data processing, and application infrastructure, but this report focuses on accelerator paths for large-scale training and inference.
+ - **Sandboxes and agent runtimes.** Browser sandboxes, code-execution environments, and isolation layers matter for agent systems, but they are not accelerator paths.
+ - **FPGAs and experimental silicon.** This report focuses on mainstream AI accelerators used for large-scale training and inference.
diff --git a/mkdocs/overrides/main.html b/mkdocs/overrides/main.html
index 123b760be..7b44419ab 100644
--- a/mkdocs/overrides/main.html
+++ b/mkdocs/overrides/main.html
@@ -228,7 +228,7 @@
{% endblock %}
{% block announce %}
-Infrastructure orchestration is an agent skill
+The state of heterogeneous AI compute in 2026
{% endblock %}
{# Footer is rendered INSIDE .md-content (above, after the article) — NOT as a full-width sibling —
diff --git a/website/src/components/SiteBanner.tsx b/website/src/components/SiteBanner.tsx
index d092e8a4e..39e4fe3ab 100644
--- a/website/src/components/SiteBanner.tsx
+++ b/website/src/components/SiteBanner.tsx
@@ -3,8 +3,8 @@ import { BLOG_URL } from '../routes';
// Top announcement banner, mirroring the one on the MkDocs docs site. It sits above the top
// nav; the two stick to the top together (see .site-header). Update the copy/href here when
// the announcement changes.
-const BANNER_TEXT = 'Infrastructure orchestration is an agent skill';
-const BANNER_HREF = `${BLOG_URL}/agentic-orchestration/`;
+const BANNER_TEXT = 'The state of heterogeneous AI compute in 2026';
+const BANNER_HREF = `${BLOG_URL}/state-of-heterogeneous-compute-2026/`;
export function SiteBanner() {
return (
diff --git a/website/src/components/SiteNavigation.tsx b/website/src/components/SiteNavigation.tsx
index 28b99d46d..116c8cfda 100644
--- a/website/src/components/SiteNavigation.tsx
+++ b/website/src/components/SiteNavigation.tsx
@@ -14,12 +14,12 @@ const dstackGithubUrl = 'https://github.com/dstackai/dstack';
const externalIconAriaLabel = 'External link icon';
// Primary links in the desktop top navigation (plain same-origin MkDocs links). The blog
-// categories are listed individually (Case studies / Benchmarks / Blog) to mirror the docs
+// categories are listed individually (Case studies / Reports / Blog) to mirror the docs
// header tabs — no "Resources" dropdown.
const audienceNavItems: Array<{ label: string; href: string }> = [
{ label: 'Docs', href: DOCS_URL },
{ label: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { label: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { label: 'Reports', href: `${BLOG_URL}/reports/` },
{ label: 'Blog', href: BLOG_URL },
];
@@ -46,7 +46,7 @@ const productDropdownItems: ButtonDropdownProps.Items = [
const mobileNavigationItems: SideNavigationProps.Item[] = [
{ type: 'link', text: 'Docs', href: DOCS_URL },
{ type: 'link', text: 'Case studies', href: `${BLOG_URL}/case-studies/` },
- { type: 'link', text: 'Benchmarks', href: `${BLOG_URL}/benchmarks/` },
+ { type: 'link', text: 'Reports', href: `${BLOG_URL}/reports/` },
{ type: 'link', text: 'Blog', href: BLOG_URL },
{ type: 'link', text: 'GitHub', href: dstackGithubUrl, external: true, externalIconAriaLabel },
{