diff --git a/.github/workflows/publish.yml b/.github/workflows/publish.yml
deleted file mode 100644
index 5c37c8f..0000000
--- a/.github/workflows/publish.yml
+++ /dev/null
@@ -1,119 +0,0 @@
-name: Publish to PyPI and TestPyPI
-
-on: push
-
-jobs:
- build:
- name: Build distribution
- runs-on: macos-latest
-
- steps:
- - uses: actions/checkout@v4
- with:
- persist-credentials: false
- - name: Set up Python
- uses: actions/setup-python@v5
- with:
- python-version: "3.x"
- - name: Install pypa/build
- run: >-
- python3 -m
- pip install
- build
- --user
- - name: Build a binary wheel and a source tarball
- run: python3 -m build
- - name: Store the distribution packages
- uses: actions/upload-artifact@v4
- with:
- name: python-package-distributions
- path: dist/
-
- publish-to-pypi:
- name: >-
- Publish to PyPI
- if: startsWith(github.ref, 'refs/tags/') # only publish to PyPI on tag pushes
- needs:
- - build
- runs-on: macos-latest
- environment:
- name: pypi
- url: https://pypi.org/p/process_manager # Replace process_manager with your PyPI project name
- permissions:
- id-token: write # IMPORTANT: mandatory for trusted publishing
-
- steps:
- - name: Download all the dists
- uses: actions/download-artifact@v4
- with:
- name: python-package-distributions
- path: dist/
- - name: Publish to PyPI
- uses: pypa/gh-action-pypi-publish@release/v1
-
- github-release:
- name: >-
- Sign with Sigstore
- and upload them to GitHub Release
- needs:
- - publish-to-pypi
- runs-on: macos-latest
-
- permissions:
- contents: write # IMPORTANT: mandatory for making GitHub Releases
- id-token: write # IMPORTANT: mandatory for sigstore
-
- steps:
- - name: Download all the dists
- uses: actions/download-artifact@v4
- with:
- name: python-package-distributions
- path: dist/
- - name: Sign the dists with Sigstore
- uses: sigstore/gh-action-sigstore-python@v3.0.0
- with:
- inputs: >-
- ./dist/*.tar.gz
- ./dist/*.whl
- - name: Create GitHub Release
- env:
- GITHUB_TOKEN: ${{ github.token }}
- run: >-
- gh release create
- "$GITHUB_REF_NAME"
- --repo "$GITHUB_REPOSITORY"
- --notes ""
- - name: Upload artifact signatures to GitHub Release
- env:
- GITHUB_TOKEN: ${{ github.token }}
- # Upload to GitHub Release using the `gh` CLI.
- # `dist/` contains the built packages, and the
- # sigstore-produced signatures and certificates.
- run: >-
- gh release upload
- "$GITHUB_REF_NAME" dist/**
- --repo "$GITHUB_REPOSITORY"
-
- publish-to-testpypi:
- name: Publish Python 🐍 distribution 📦 to TestPyPI
- needs:
- - build
- runs-on: macos-latest
-
- environment:
- name: testpypi
- url: https://test.pypi.org/p/process_manager
-
- permissions:
- id-token: write # IMPORTANT: mandatory for trusted publishing
-
- steps:
- - name: Download all the dists
- uses: actions/download-artifact@v4
- with:
- name: python-package-distributions
- path: dist/
- - name: Publish to TestPyPI
- uses: pypa/gh-action-pypi-publish@release/v1
- with:
- repository-url: https://test.pypi.org/legacy/
\ No newline at end of file
diff --git a/.github/workflows/workflow.yml b/.github/workflows/workflow.yml
new file mode 100644
index 0000000..d6933ab
--- /dev/null
+++ b/.github/workflows/workflow.yml
@@ -0,0 +1,80 @@
+name: "Publish"
+
+on:
+ push:
+ branches: ["main"] # Run tests on every push to main
+ tags: ["v*"] # Run tests AND publish on tags
+ pull_request:
+ branches: ["main"] # Run tests on PRs
+
+jobs:
+ test:
+ name: "Test (Python ${{ matrix.python-version }})"
+ runs-on: ubuntu-latest
+ strategy:
+ matrix:
+ # Parallelize tests across your supported versions
+ python-version: ["3.12", "3.13", "3.14"]
+
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v4
+
+ - name: Install uv
+ uses: astral-sh/setup-uv@v5
+ with:
+ enable-cache: true
+
+ - name: Install Python ${{ matrix.python-version }}
+ run: uv python install ${{ matrix.python-version }}
+
+ - name: Run unit tests
+ # Explicitly tells uv which python version to use for the test environment
+ run: uv run --python ${{ matrix.python-version }} --group dev pytest
+ publish:
+ name: "Build and Publish"
+ needs: [test]
+ # ONLY run this job if the push was actually a tag
+ if: startsWith(github.ref, 'refs/tags/v')
+ runs-on: ubuntu-latest
+ environment:
+ name: pypi
+ permissions:
+ id-token: write # Required for PyPI Trusted Publishing
+ contents: write # Required to create GitHub Release and upload assets
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v6
+ with:
+ # Fetch all history so we can see other branches
+ fetch-depth: 0
+
+ - name: Verify Tag is on Main
+ # Only perform this check if we were triggered by a tag
+ if: startsWith(github.ref, 'refs/tags/v')
+ run: |
+ # Check if 'main' branch contains the current commit
+ if ! git branch -r --contains ${{ github.sha }} | grep -q "origin/main"; then
+ echo "::error::Tag ${{ github.ref_name }} was pushed on a non-main branch. Skipping workflow."
+ exit 1
+ fi
+
+ - name: Install uv
+ uses: astral-sh/setup-uv@v7
+
+ - name: Install Python 3.13
+ run: uv python install 3.13
+
+ - name: Build
+ run: uv build
+
+ - name: Publish to PyPI
+ run: uv publish --check-url https://pypi.org/simple
+
+ - name: Create GitHub Release
+ uses: softprops/action-gh-release@v2
+ with:
+ generate_release_notes: true
+ files: |
+ dist/*.whl
+ dist/*.tar.gz
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 522f493..42f9aca 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -27,3 +27,12 @@ repos:
rev: v1.1.408
hooks:
- id: pyright
+ - repo: local
+ hooks:
+ - id: act-test
+ name: Run GitHub Actions locally (act)
+ entry: act -j test
+ language: system
+ stages: [pre-push]
+ pass_filenames: false
+ files: ^(src/|tests/|pyproject\.toml|uv\.lock)
diff --git a/LICENSE.txt b/LICENSE.txt
index b2e15bb..ae4fe8b 100644
--- a/LICENSE.txt
+++ b/LICENSE.txt
@@ -1,21 +1,201 @@
-MIT License
-
-Copyright (c) 2025 TalbotKnighton
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all
-copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2026 David Gable
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
index ee18cbc..07871b5 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,75 @@
+
+
-[Read the Docs](https://talbotknighton.github.io/process_manager/)
+# stochas: Smart Data Orchestration
-[View on PyPi](https://pypi.org/project/process_manager/)
\ No newline at end of file
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+`stochas` is a Python framework built to handle the complexity of **Monte Carlo simulations**, **parametric studies**, and **probabilistic modeling**.
+
+It provides a robust bridge between abstract statistical rules and concrete simulation data, ensuring your experiments are repeatable, traceable, and easy to manage.
+
+---
+
+## Installation
+
+Install the package via your preferred manager:
+
+```bash
+uv add stochas
+```
+
+or with `pip`:
+
+```bash
+pip install stochas
+```
+
+---
+
+## Core Features
+
+- **Salted Seeding**: Combines Global Seeds, Parameter Names, and Trial Numbers for unique but deterministic draws.
+- **Numeric Mixins**: Use your data containers directly in math operations (`container * 5.0`) without manually extracting values.
+- **Nominal Support**: Easily toggle between "Perfect World" (Trial 0) and "Probabilistic World" (Monte Carlo) results.
+- **Pydantic Foundation**: Every component is a Pydantic model, providing out-of-the-box validation and effortless JSON serialization.
+
+---
+
+## Why use `stochas`?
+
+Managing hundreds of simulation trials can quickly become a mess of manual seeds and inconsistent data. `stochas` solves this by providing:
+
+- **Repeatable Randomness**: Our "Salted Seed" logic ensures that any specific trial can be perfectly recreated, even years later, by tying randomness to simple to set and store values.
+- **Smart Containers**: `NamedValue` objects behave like numbers or arrays but protect your data from accidental overwrites using a state-machine logic.
+- **Physics-Ready Distributions**: A wide range of built-in distributions (Normal, Truncated Normal, Log-Normal, etc.) that handle their own random number generators internally.
+- **Serialized Registries**: Automatically track exactly which "rules" (`Distributions`) and "results" (`NamedValues`) were used in every trial for easy export to JSON or databases.
diff --git a/docs/assets/distributions/bernoulli.png b/docs/assets/distributions/bernoulli.png
index 65df77b..88d13f4 100644
Binary files a/docs/assets/distributions/bernoulli.png and b/docs/assets/distributions/bernoulli.png differ
diff --git a/docs/assets/distributions/categorical.png b/docs/assets/distributions/categorical.png
index d021b1f..a7f4b6f 100644
Binary files a/docs/assets/distributions/categorical.png and b/docs/assets/distributions/categorical.png differ
diff --git a/docs/assets/distributions/discrete_uniform.png b/docs/assets/distributions/discrete_uniform.png
new file mode 100644
index 0000000..da63e2a
Binary files /dev/null and b/docs/assets/distributions/discrete_uniform.png differ
diff --git a/docs/assets/distributions/exponential.png b/docs/assets/distributions/exponential.png
index b282c60..69867f8 100644
Binary files a/docs/assets/distributions/exponential.png and b/docs/assets/distributions/exponential.png differ
diff --git a/docs/assets/distributions/gen_distribution_figures.py b/docs/assets/distributions/gen_distribution_figures.py
index 3b2bea7..4fb03fd 100644
--- a/docs/assets/distributions/gen_distribution_figures.py
+++ b/docs/assets/distributions/gen_distribution_figures.py
@@ -1,28 +1,35 @@
+from collections.abc import Sequence
+from dataclasses import dataclass
from enum import StrEnum
from pathlib import Path
+from typing import Any, cast
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.axes import Axes
+from matplotlib.colors import to_hex, to_rgb
from matplotlib.figure import Figure
-from process_manager import (
+from stochas import (
BernoulliDistribution,
CategoricalDistribution,
+ DiscreteUniformDistribution,
+ Dist,
DistName,
DistType,
ExponentialDistribution,
LogNormalDistribution,
NormalDistribution,
PoissonDistribution,
+ RayleighDistribution,
TriangularDistribution,
TruncatedNormalDistribution,
UniformDistribution,
)
ASSET_DIR = Path(__file__).parent
-ORANGE = "#FF5F05"
-BLUE = "#13294B"
+ROSE_500 = "#f43f5e"
+SKY_500 = "#0ea5e9"
DPI = 200
ASPECT_RATIO = 12 / 5
@@ -31,36 +38,43 @@
HEIGHT = WIDTH / ASPECT_RATIO
-def get_dist(
- dist_type: DistType,
-) -> tuple[
- BernoulliDistribution
- | CategoricalDistribution
- | ExponentialDistribution
- | LogNormalDistribution
- | NormalDistribution
- | PoissonDistribution
- | TriangularDistribution
- | TruncatedNormalDistribution
- | UniformDistribution,
- str,
-]:
+@dataclass
+class DistSweep:
+ """A family of same-typed distributions, varying one "critical" parameter."""
+
+ distributions: Sequence[Dist]
+ labels: list[str]
+ sup_title: str
+
+
+DiscreteDist = BernoulliDistribution | PoissonDistribution | DiscreteUniformDistribution
- name = DistName(dist_type)
- sup_title = f"{name.replace('_', ' ').title()} Distribution "
+def get_dist_sweep(dist_type: DistType) -> DistSweep | None:
+ name = DistName(dist_type)
+ sup_title = f"{name.replace('_', ' ').title()} Distribution"
match dist_type:
case DistType.NORMAL:
- mu = 0
- sigma = 1
- dist = NormalDistribution(name=name, mu=mu, sigma=sigma)
- sup_title += f"({mu=} {sigma=})"
+ sigmas = [0.5, 1.0, 2.0]
+ dists = [
+ NormalDistribution(name=name, mu=0, sigma=sigma) for sigma in sigmas
+ ]
+ labels = [f"sigma={sigma}" for sigma in sigmas]
+ sup_title += " (sweeping sigma)"
case DistType.UNIFORM:
- low = -1
- high = 2
- dist = UniformDistribution(name=name, low=low, high=high)
- sup_title += f"({low=} {high=})"
+ highs = [1.0, 2.0, 4.0]
+ dists = [UniformDistribution(name=name, low=0, high=high) for high in highs]
+ labels = [f"[0, {high}]" for high in highs]
+ sup_title += " (sweeping high)"
+ case DistType.DISCRETE_UNIFORM:
+ highs = [2, 5, 10]
+ dists = [
+ DiscreteUniformDistribution(name=name, low=0, high=high)
+ for high in highs
+ ]
+ labels = [f"[0, {high}]" for high in highs]
+ sup_title += " (sweeping high)"
case DistType.CATEGORICAL:
class Blood(StrEnum):
@@ -73,162 +87,195 @@ class Blood(StrEnum):
AB_P = "AB+"
AB_N = "AB-"
- dist = CategoricalDistribution[Blood](
- name=name,
- choices={
- Blood.O_P: 0.36,
- Blood.O_N: 0.14,
- Blood.A_P: 0.28,
- Blood.A_N: 0.08,
- Blood.B_P: 0.08,
- Blood.B_N: 0.03,
- Blood.AB_P: 0.02,
- Blood.AB_N: 0.01,
- },
- nominal=Blood.O_P,
- )
- sup_title += "(blood types)"
+ dists = [
+ CategoricalDistribution[Blood](
+ name=name,
+ choices={
+ Blood.O_P: 0.36,
+ Blood.O_N: 0.14,
+ Blood.A_P: 0.28,
+ Blood.A_N: 0.08,
+ Blood.B_P: 0.08,
+ Blood.B_N: 0.03,
+ Blood.AB_P: 0.02,
+ Blood.AB_N: 0.01,
+ },
+ nominal=Blood.O_P,
+ )
+ ]
+ labels = ["blood types"]
+ sup_title += " (blood types)"
case DistType.TRIANGULAR:
- low = 0
- high = 1
- mode = 0.75
- dist = TriangularDistribution(name=name, low=low, high=high, mode=mode)
- sup_title += f"({low=} {high=} {mode=})"
+ modes = [0.25, 0.5, 0.75]
+ dists = [
+ TriangularDistribution(name=name, low=0, high=1, mode=mode)
+ for mode in modes
+ ]
+ labels = [f"mode={mode}" for mode in modes]
+ sup_title += " (sweeping mode)"
case DistType.TRUNCATED_NORMAL:
- mu = 1
- sigma = 1
- low = 0
- dist = TruncatedNormalDistribution(name=name, mu=mu, sigma=sigma, low=low)
- sup_title += f"({mu=} {sigma=} {low=})"
+ lows = [-2.0, -1.0, 0.0]
+ dists = [
+ TruncatedNormalDistribution(name=name, mu=0, sigma=1, low=low)
+ for low in lows
+ ]
+ labels = [f"low={low}" for low in lows]
+ sup_title += " (sweeping low)"
case DistType.LOG_NORMAL:
- s = 1
- scale = 1
- dist = LogNormalDistribution(name=name, s=s, scale=scale)
- sup_title += f"({s=} {scale=})"
+ shapes = [0.25, 0.5, 1.0]
+ dists = [LogNormalDistribution(name=name, s=s, scale=1) for s in shapes]
+ labels = [f"s={s}" for s in shapes]
+ sup_title += " (sweeping s)"
case DistType.POISSON:
- lam = 4
- dist = PoissonDistribution(name=name, lam=lam)
- sup_title += f"({lam=})"
+ lams = [1.0, 4.0, 10.0]
+ dists = [PoissonDistribution(name=name, lam=lam) for lam in lams]
+ labels = [f"λ={lam}" for lam in lams]
+ sup_title += " (sweeping λ)"
case DistType.EXPONENTIAL:
- lam = 1
- dist = ExponentialDistribution(name=name, lam=lam)
- sup_title += f"({lam=})"
+ lams = [0.5, 1.0, 2.0]
+ dists = [ExponentialDistribution(name=name, lam=lam) for lam in lams]
+ labels = [f"λ={lam}" for lam in lams]
+ sup_title += " (sweeping λ)"
+ case DistType.RAYLEIGH:
+ scales = [0.5, 1.0, 2.0]
+ dists = [RayleighDistribution(name=name, scale=scale) for scale in scales]
+ labels = [f"scale={scale}" for scale in scales]
+ sup_title += " (sweeping scale)"
case DistType.BERNOULLI:
- p = 0.75
- dist = BernoulliDistribution(name=name, p=p)
- sup_title += f"({p=})"
+ ps = [0.25, 0.5, 0.75]
+ dists = [BernoulliDistribution(name=name, p=p) for p in ps]
+ labels = [f"p={p}" for p in ps]
+ sup_title += " (sweeping p)"
case _:
- raise NotImplementedError(
- f"Distribution of type {dist_type} is not implemented"
- )
+ print(f"Distribution of type {dist_type} is not implemented")
+ return None
- return dist, sup_title
-
-
-def plot_and_save(
- dist: BernoulliDistribution
- | CategoricalDistribution
- | ExponentialDistribution
- | LogNormalDistribution
- | NormalDistribution
- | PoissonDistribution
- | TriangularDistribution
- | TruncatedNormalDistribution
- | UniformDistribution,
- sup_title: str,
-):
- """Generates a dual-panel plot for a distribution and saves it."""
+ return DistSweep(distributions=dists, labels=labels, sup_title=sup_title)
+
+
+def shades(base_color: str, n: int) -> list[tuple[float, float, float]]:
+ """Returns n shades of base_color, from a light tint to the full color."""
+ base = np.array(to_rgb(base_color))
+ white = np.array([1.0, 1.0, 1.0])
+ if n == 1:
+ return [tuple(base)]
+ fracs = np.linspace(0.7, 0.0, n)
+ return [tuple((1 - f) * base + f * white) for f in fracs]
+
+
+def plot_and_save_sweep(sweep: DistSweep):
+ """Generates a dual-panel plot for a family of distributions and saves it."""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(WIDTH, HEIGHT))
fig: Figure
ax1: Axes
ax2: Axes
- # Determine support/range
- if dist.is_continuous:
- # Use PPF to find reasonable bounds (0.1% to 99.9%)
+ n = len(sweep.distributions)
+ pdf_colors = shades(ROSE_500, n)
+ cdf_colors = shades(SKY_500, n)
+ first = sweep.distributions[0]
+
+ if first.is_continuous:
+ # use ppf to find a shared support across the whole sweep (0.1% to 99.9%)
try:
- x_min, x_max = dist.ppf(0.001), dist.ppf(0.999)
- except Exception: # Fallback for edge cases
+ bounds = [
+ (dist.ppf(0.001), dist.ppf(0.999)) for dist in sweep.distributions
+ ]
+ x_min = min(lo for lo, _ in bounds)
+ x_max = max(hi for _, hi in bounds)
+ except Exception: # fallback for edge cases
x_min, x_max = -5, 5
x = np.linspace(x_min, x_max, 500)
- y_pdf = dist.pdf(x)
- y_cdf = dist.cdf(x)
- # Plot PDF with shading
- ax1.plot(x, y_pdf, lw=2, color=ORANGE)
- ax1.fill_between(x, y_pdf, alpha=0.2, color=ORANGE)
- ax1.set_ylabel("Density (PDF)")
+ for dist, label, pdf_color, cdf_color in zip(
+ sweep.distributions, sweep.labels, pdf_colors, cdf_colors
+ ):
+ y_pdf = dist.pdf(x)
+ y_cdf = dist.cdf(x)
+
+ ax1.plot(x, y_pdf, lw=2, color=pdf_color, label=label)
+ ax1.fill_between(x, y_pdf, alpha=0.1, color=pdf_color)
- # Plot CDF with shading
- ax2.plot(x, y_cdf, lw=2, color=BLUE)
- ax2.fill_between(x, y_cdf, alpha=0.2, color=BLUE)
+ ax2.plot(x, y_cdf, lw=2, color=cdf_color, label=label)
+
+ ax1.set_ylabel("Density (PDF)")
ax2.set_ylabel("Cumulative Prob (CDF)")
- else:
- # Discrete logic (Bernoulli, Poisson, Categorical)
- if isinstance(dist, CategoricalDistribution):
- x = np.arange(len(dist.choices))
- eval_at = dist.categories
- labels = [str(c) for c in dist.choices]
-
- ax1.set_xticks(x, labels, rotation=45)
- ax2.set_xticks(x, labels, rotation=45)
- else:
- if isinstance(dist, PoissonDistribution):
- x = np.arange(0, 10)
- eval_at = x
- elif isinstance(dist, BernoulliDistribution):
- x = np.array([0, 1])
- eval_at = x
- else:
- raise NotImplementedError(
- f"Distribution of {type(dist)=} not supported"
- )
- labels = x
-
- y_pmf = [dist.pmf(val) for val in eval_at] # pyright: ignore[reportArgumentType]
- y_cdf = [dist.cdf(val) for val in eval_at] # pyright: ignore[reportArgumentType]
-
- # Plot PMF
- ax1.stem(
- x,
- y_pmf, # pyright: ignore[reportArgumentType]
- basefmt=" ",
- linefmt=ORANGE,
- markerfmt="o",
+ elif isinstance(first, CategoricalDistribution):
+ categorical_dists = cast(
+ "list[CategoricalDistribution[Any]]", sweep.distributions
)
- ax1.set_ylabel("Probability (PMF)")
- # Plot CDF (Step)
- ax2.step(x, y_cdf, where="post", color=BLUE, lw=2) # pyright: ignore[reportArgumentType]
- ax2.fill_between(x, y_cdf, step="post", alpha=0.2, color=BLUE) # pyright: ignore[reportArgumentType]
+ x = np.arange(len(first.choices))
+ eval_at = first.categories
+ tick_labels = [str(c) for c in first.choices]
+ ax1.set_xticks(x, tick_labels, rotation=45)
+ ax2.set_xticks(x, tick_labels, rotation=45)
+
+ for dist, label, pdf_color, cdf_color in zip(
+ categorical_dists, sweep.labels, pdf_colors, cdf_colors
+ ):
+ y_pmf = [dist.pmf(val) for val in eval_at]
+ y_cdf = [dist.cdf(val) for val in eval_at]
+
+ ax1.stem(
+ x,
+ y_pmf,
+ basefmt=" ",
+ linefmt=to_hex(pdf_color),
+ markerfmt="o",
+ label=label,
+ )
+ ax2.step(x, y_cdf, where="post", color=cdf_color, lw=2, label=label)
- # Optional: step plots don't fill_between well, but you can fill_between x and y_cdf
- # with step mode if you really want color under the staircase.
+ ax1.set_ylabel("Probability (PMF)")
ax2.set_ylabel("Cumulative Prob (CDF)")
- # Cleanup and labeling
+ else:
+ discrete_dists = cast("list[DiscreteDist]", sweep.distributions)
+ # use ppf to find a shared integer support across the sweep
+ bounds = [(dist.ppf(0.001), dist.ppf(0.999)) for dist in discrete_dists]
+ x_min = int(np.floor(min(lo for lo, _ in bounds)))
+ x_max = int(np.ceil(max(hi for _, hi in bounds)))
+ x = list(range(x_min, x_max + 1))
+
+ for dist, label, pdf_color, cdf_color in zip(
+ discrete_dists, sweep.labels, pdf_colors, cdf_colors
+ ):
+ y_pmf = np.asarray([dist.pmf(val) for val in x], dtype=float)
+ y_cdf = np.asarray([dist.cdf(val) for val in x], dtype=float)
+
+ ax1.plot(x, y_pmf, "o-", color=pdf_color, label=label)
+ ax2.step(x, y_cdf, where="post", color=cdf_color, lw=2, label=label)
+
+ ax1.set_ylabel("Probability (PMF)")
+ ax2.set_ylabel("Cumulative Prob (CDF)")
+
+ # cleanup and labeling
ax1.set_ylim(bottom=0)
ax2.set_ylim(bottom=0)
- fig.suptitle(sup_title, fontsize=14)
+ fig.suptitle(sweep.sup_title, fontsize=14)
for ax in [ax1, ax2]:
ax.grid(True, alpha=0.3)
ax.set_xlabel("Value")
+ if n > 1:
+ ax1.legend(fontsize=8)
+
fig.tight_layout()
- fig.savefig(ASSET_DIR / f"{dist.dist_type.lower()}.png", dpi=DPI)
+ fig.savefig(ASSET_DIR / f"{first.dist_type.lower()}.png", dpi=DPI)
plt.close(fig)
def main():
for dist_type in DistType:
print(f"{dist_type=}")
- dist, label = get_dist(dist_type)
- plot_and_save(dist, label)
- # breakpoint()
+ sweep = get_dist_sweep(dist_type)
+ if sweep:
+ plot_and_save_sweep(sweep)
if __name__ == "__main__":
diff --git a/docs/assets/distributions/log_normal.png b/docs/assets/distributions/log_normal.png
index 1c55ede..272ccc2 100644
Binary files a/docs/assets/distributions/log_normal.png and b/docs/assets/distributions/log_normal.png differ
diff --git a/docs/assets/distributions/normal.png b/docs/assets/distributions/normal.png
index e1a7cb0..1191ded 100644
Binary files a/docs/assets/distributions/normal.png and b/docs/assets/distributions/normal.png differ
diff --git a/docs/assets/distributions/poisson.png b/docs/assets/distributions/poisson.png
index 55f6665..cd18314 100644
Binary files a/docs/assets/distributions/poisson.png and b/docs/assets/distributions/poisson.png differ
diff --git a/docs/assets/distributions/rayleigh.png b/docs/assets/distributions/rayleigh.png
new file mode 100644
index 0000000..d85be2a
Binary files /dev/null and b/docs/assets/distributions/rayleigh.png differ
diff --git a/docs/assets/distributions/triangular.png b/docs/assets/distributions/triangular.png
index c3d1aa6..0694050 100644
Binary files a/docs/assets/distributions/triangular.png and b/docs/assets/distributions/triangular.png differ
diff --git a/docs/assets/distributions/truncated_normal.png b/docs/assets/distributions/truncated_normal.png
index 873d237..e5728ad 100644
Binary files a/docs/assets/distributions/truncated_normal.png and b/docs/assets/distributions/truncated_normal.png differ
diff --git a/docs/assets/distributions/uniform.png b/docs/assets/distributions/uniform.png
index 583d226..a71f150 100644
Binary files a/docs/assets/distributions/uniform.png and b/docs/assets/distributions/uniform.png differ
diff --git a/docs/assets/gh-social.png b/docs/assets/gh-social.png
new file mode 100644
index 0000000..ef5388d
Binary files /dev/null and b/docs/assets/gh-social.png differ
diff --git a/docs/assets/logo.svg b/docs/assets/logo.svg
new file mode 100644
index 0000000..8067ff2
--- /dev/null
+++ b/docs/assets/logo.svg
@@ -0,0 +1,483 @@
+
+
+
+STOCHAS
+
+
+# stochas: Smart Data Orchestration
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+`stochas` is a Pythons framework built to handle the complexity of **Monte Carlo simulations**, **parametric studies**, and **probabilistic modeling**.
It provides a robust bridge between abstract statistical rules and concrete simulation data, ensuring your experiments are repeatable, traceable, and easy to manage.
@@ -12,32 +61,32 @@ Install the package via your preferred manager:
=== "`uv`"
- ```bash
- uv add process_manager
+ ```bash linenums="0"
+ uv add stochas
```
=== "`pip`"
- ```bash
- pip install process_manager
+ ```bash linenums="0"
+ pip install stochas
```
---
## Core Features
-* **Salted Seeding**: Combines Global Seeds, Parameter Names, and Trial Numbers for unique but deterministic draws.
-* **Numeric Mixins**: Use your data containers directly in math operations (`container * 5.0`) without manually extracting values.
-* **Nominal Support**: Easily toggle between "Perfect World" (Trial 0) and "Probabilistic World" (Monte Carlo) results.
-* **Pydantic Foundation**: Every component is a Pydantic model, providing out-of-the-box validation and effortless JSON serialization.
+- **Salted Seeding**: Combines Global Seeds, Parameter Names, and Trial Numbers for unique but deterministic draws.
+- **Numeric Mixins**: Use your data containers directly in math operations (`container * 5.0`) without manually extracting values.
+- **Nominal Support**: Easily toggle between "Perfect World" (Trial 0) and "Probabilistic World" (Monte Carlo) results.
+- **Pydantic Foundation**: Every component is a Pydantic model, providing out-of-the-box validation and effortless JSON serialization.
---
-## Why use `process_manager`?
+## Why use `stochas`?
-Managing hundreds of simulation trials can quickly become a mess of manual seeds and inconsistent data. `process_manager` solves this by providing:
+Managing hundreds of simulation trials can quickly become a mess of manual seeds and inconsistent data. `stochas` solves this by providing:
-* **Repeatable Randomness**: Our "Salted Seed" logic ensures that any specific trial can be perfectly recreated, even years later, by tying randomness to simple to set and store values.
-* **Smart Containers**: `NamedValue` objects behave like numbers or arrays but protect your data from accidental overwrites using a state-machine logic.
-* **Physics-Ready Distributions**: A wide range of built-in distributions (Normal, Truncated Normal, Log-Normal, etc.) that handle their own random number generators internally.
-* **Serialized Registries**: Automatically track exactly which "rules" (`Distributions`) and "results" (`NamedValues`) were used in every trial for easy export to JSON or databases.
+- **Repeatable Randomness**: Our "Salted Seed" logic ensures that any specific trial can be perfectly recreated, even years later, by tying randomness to simple to set and store values.
+- **Smart Containers**: `NamedValue` objects behave like numbers or arrays but protect your data from accidental overwrites using a state-machine logic.
+- **Physics-Ready Distributions**: A wide range of built-in distributions (Normal, Truncated Normal, Log-Normal, etc.) that handle their own random number generators internally.
+- **Serialized Registries**: Automatically track exactly which "rules" (`Distributions`) and "results" (`NamedValues`) were used in every trial for easy export to JSON or databases.
diff --git a/docs/javascripts/katex.js b/docs/javascripts/katex.js
new file mode 100644
index 0000000..0946ce0
--- /dev/null
+++ b/docs/javascripts/katex.js
@@ -0,0 +1,10 @@
+document$.subscribe(({ body }) => {
+ renderMathInElement(body, {
+ delimiters: [
+ { left: "$$", right: "$$", display: true },
+ { left: "$", right: "$", display: false },
+ { left: "\\(", right: "\\)", display: false },
+ { left: "\\[", right: "\\]", display: true },
+ ],
+ });
+});
diff --git a/docs/user-guides/design-values.md b/docs/user-guides/design-values.md
new file mode 100644
index 0000000..1245725
--- /dev/null
+++ b/docs/user-guides/design-values.md
@@ -0,0 +1,84 @@
+# Design Values: Evolving Your System
+
+!!! abstract
+ **Design Values** represent the controllable "knobs" of your simulation, defining the mathematical search space for automated optimization. Unlike random distributions, which assess reliability, these variables empower solvers like `optuna` and `pymoo` to navigate complex performance landscapes and identify optimal system trade-offs. This guide covers the Search Space API, solver-agnostic integration patterns, and the automated refinement process for narrowing in on high-precision "Golden Case" solutions.
+
+---
+
+While Distributions represent the uncertainty you can't control (like wind or manufacturing tolerances), Design Values represent the parameters you can control. These are the knobs you turn to find the absolute best version of your system.
+
+## Optimization vs. Randomness
+
+In a generic design workflow, we distinguish between two types of variables:
+
+| Feature | Monte Carlo (Distributions) | Optimization (Design Values) |
+|:------------|:-------------------------------------|:-----------------------------------------|
+| **Goal** | Assess reliability and error bounds. | Find peak performance or trade-offs. |
+| **Logic** | Values are drawn from a PDF/PMF. | Values are chosen by a search algorithm. |
+| **Tooling** | Standard statistical sampling. | Optuna (Tuning) or pymoo (Pareto). |
+
+---
+
+## The Search Space API
+
+Design values define a "Search Space"—a mathematical boundary that an optimizer is allowed to explore. Every design variable in your registry must provide three things:
+
+1. A Name: To track the variable across trials.
+2. A Default: The initial "best guess" before the optimizer starts.
+3. Bounds: The constraints (low/high or choices) that the solver must respect.
+
+### Supported Variable Types
+
+| Type | Data | Best Used For... |
+|:--------------------|:---------------------------|:-------------------------------------------------|
+| `DesignFloat` | $x \in [low, high]$ | Continuous values like stiffness or damping. |
+| `DesignInt` | $i \in \{low, ..., high\}$ | Discrete counts like solver iterations or parts. |
+| `DesignBool` |$\{True, False\}$ | Enabling/disabling specific logic branches. |
+| `DesignCategorical` | $\{'A', 'B', 'C'\}$ | Picking between distinct materials or styles. |
+
+---
+
+## Integrating with Solvers
+
+One of the primary advantages of this toolkit is its Solver-Agnostic nature. Your model defines the variables once, and the system can automatically translate them into the specific language of different optimization libraries.
+
+### Optuna Integration (`to_optuna`)
+
+For single-objective tuning, the variable suggests a value to a trial.
+
+- **Continuous:** Uses Bayesian TPE or CMA-ES sampling.
+- **Refinement:** The refine method allows the search space to "shrink" around the best known solution for more precision.
+
+### pymoo Integration (`to_pymoo`)
+
+For multi-objective trade-offs, the variable generates a pymoo.core.variable object.
+
+- **Population-based:** Allows for genetic operators (Crossover and Mutation).
+- **Pareto Front:** Enables the discovery of the frontier of efficiency.
+
+---
+
+## Usage Example
+
+The following script demonstrates how to define a generic "System" and sample design variables into a registry for optimization.
+
+```python
+--8<-- "docs/user-guides/design_values.py"
+```
+
+---
+
+## Search Space Refinement
+
+When you reach the end of an optimization study, you may find that the "best" trial is settled in a specific neighborhood. The `refine` method automates the "zoom-in" process.
+
+Given a refinement factor $F \in (0, 1)$ and the best known value $x_{best}$, the new bounds are calculated as:
+
+$$low_{new} = \max(low_{old}, x_{best} - \frac{(high_{old} - low_{old}) \cdot F}{2})$$
+
+$$high_{new} = \min(high_{old}, x_{best} + \frac{(high_{old} - low_{old}) \cdot F}{2})$$
+
+---
+
+!!! success
+ By using the `sample_design` pattern, you have decoupled your **Design Intent** from the **Optimization Math**. You can switch from Optuna's Bayesian search to pymoo's Genetic algorithms without changing a single line of your model generation logic.
diff --git a/docs/user-guides/design_values.py b/docs/user-guides/design_values.py
new file mode 100644
index 0000000..347b915
--- /dev/null
+++ b/docs/user-guides/design_values.py
@@ -0,0 +1,74 @@
+import logging
+
+import numpy as np
+import optuna
+
+import stochas
+
+# Setup logging
+logging.basicConfig(level=logging.INFO)
+
+
+class SystemModel(stochas.StochasBase):
+ """A generic system model that uses design variables."""
+
+ pass
+
+
+def generate_system(model: SystemModel):
+ # 1. Define a continuous float (e.g., structural stiffness)
+ # The optimizer will explore between 50 and 500.
+ stiffness = model.sample_design(
+ stochas.DesignFloat(
+ name=stochas.ValueName("k_stiffness"),
+ low=50.0,
+ high=500.0,
+ stored_value=150.0, # the initial guess
+ )
+ )
+
+ # 2. Define an integer count (e.g., number of supports)
+ n_supports = model.sample_design(
+ stochas.DesignInt(
+ name=stochas.ValueName("n_supports"), low=2, high=8, stored_value=4
+ )
+ )
+
+ # 3. Define a categorical choice (e.g., material type)
+ material = model.sample_design(
+ stochas.DesignCategorical(
+ name=stochas.ValueName("material"),
+ choices=["aluminum", "steel", "titanium"],
+ stored_value="steel",
+ )
+ )
+
+ print(
+ f"Generated System: {material} frame, {n_supports} supports, k={stiffness:.2f}"
+ )
+
+
+# --- Optimization Workflow ---
+
+# 1. Create a model
+model = SystemModel()
+
+# 2. Discovery Pass: Map the design space
+generate_system(model)
+design_space = model.design
+
+# 3. Translate to Optuna
+study = optuna.create_study(direction="minimize")
+
+
+def objective(trial):
+ # Ask variables to suggest values to Optuna
+ suggestions = {name: dv.to_optuna(trial) for name, dv in design_space.items()}
+
+ # In a real run, you'd apply these 'suggestions' to the model.named registry
+ # and execute your physics/cost simulation here.
+ score = np.random.random() # Placeholder for simulation result
+ return score
+
+
+study.optimize(objective, n_trials=10)
diff --git a/docs/user-guides/distributions.md b/docs/user-guides/distributions.md
index 04062fc..e884659 100644
--- a/docs/user-guides/distributions.md
+++ b/docs/user-guides/distributions.md
@@ -1,5 +1,8 @@
# Distributions: Defining the Rules of Chance
+!!! abstract
+ **Distributions** serve as the probabilistic blueprints for your simulation's uncertainty. By defining the "shape" of possible variations, they enable rigorous Monte Carlo analysis. This guide details the mechanics of **Salted Seeds** for deterministic reproducibility, the distinction between configuration registries (`DistributionDict`) and result registries (`NamedValueDict`), and the core workflows for both locked and repeated sampling.
+
---
A **Distribution** is a mathematical recipe for generating random numbers. While a `NamedValue` represents a single point in time, a `Distribution` represents the "shape" of all possible values.
@@ -25,23 +28,25 @@ A `DistributionDict` acts as a centralized record of the "rules" used during a s
This is critical for:
-* **Serialization**: Saving exactly what settings were used so a colleague can recreate the simulation.
-* **Bulk Updates**: Changing the `trial_num` for every distribution at once as the simulation progresses.
+- **Serialization**: Saving exactly what settings were used so a colleague can recreate the simulation.
+- **Bulk Updates**: Changing the `trial_num` for every distribution at once as the simulation progresses.
### Supported Distribution Types
!!! info
- [Click here to see the technical API for all supported types][process_manager.distribution].
-
-* **Normal**: The classic Bell Curve for natural variation.
-* **Uniform**: For strict ranges where any value is equally likely.
-* **Categorical**: To pick from a fixed set of named choices (e.g., Materials).
-* **Bernoulli**: A simple True/False coin flip.
-* **Truncated Normal**: A Bell Curve with hard physical limits (e.g., mass cannot be negative).
-* **Log Normal**: For positive values with "long-tail" outliers (e.g., contact forces).
-* **Triangular**: A simpler alternative to Normal when you only know min, max, and peak.
-* **Poisson / Exponential**: For modeling the frequency or time between random events.
-* **Permutation**: To return a shuffled version of a master list.
+ [Click here to see the technical API for all supported types][stochas.distribution].
+
+- **Normal**: The classic Bell Curve for natural variation.
+- **Uniform**: For strict ranges where any value is equally likely.
+- **Discrete Uniform**: Similar to a uniform distribution, but only allows for integers to be returned.
+- **Categorical**: To pick from a fixed set of named choices (e.g., Materials).
+- **Bernoulli**: A simple True/False coin flip.
+- **Truncated Normal**: A Bell Curve with hard physical limits (e.g., mass cannot be negative).
+- **Log Normal**: For positive values with "long-tail" outliers (e.g., contact forces).
+- **Triangular**: A simpler alternative to Normal when you only know min, max, and peak.
+- **Poisson / Exponential**: For modeling the frequency or time between random events.
+- **Rayleigh**: For modeling the magnitude of a 2D vector with independent Normal components (e.g., radial positioning error).
+- **Permutation**: To return a shuffled version of a master list.
---
diff --git a/docs/user-guides/distributions.py b/docs/user-guides/distributions.py
index fe9adc8..b094238 100644
--- a/docs/user-guides/distributions.py
+++ b/docs/user-guides/distributions.py
@@ -1,18 +1,18 @@
# ---8<--- [start: basics]
from numpydantic import NDArray
-import process_manager as pm
+import stochas
# 1. Define the rule
-motor_rule = pm.NormalDistribution(
- name=pm.DistName("motor_torque"),
+motor_rule = stochas.NormalDistribution(
+ name=stochas.DistName("motor_torque"),
mu=5.0,
sigma=0.2,
)
# 2. Setup the registries
-rules = pm.DistributionDict()
-results = pm.NamedValueDict[NDArray]()
+rules = stochas.DistributionDict()
+results = stochas.NamedValueDict[NDArray]()
# 3. Sample and Register
# This returns a NamedValue and saves it to 'results'
@@ -30,12 +30,12 @@
print(val_1.value == val_2.value) # True
# ---8<--- [end: basics]
# ---8<--- [start: repeat_draw]
-rules = pm.DistributionDict()
-results = pm.NamedValueDict[NDArray]()
+rules = stochas.DistributionDict()
+results = stochas.NamedValueDict[NDArray]()
friction_rule = (
- pm.UniformDistribution(
- name=pm.DistName("friction"),
+ stochas.UniformDistribution(
+ name=stochas.DistName("friction"),
low=0.2,
high=0.4,
)
diff --git a/docs/user-guides/named-values.md b/docs/user-guides/named-values.md
index b4c692c..b8a39c0 100644
--- a/docs/user-guides/named-values.md
+++ b/docs/user-guides/named-values.md
@@ -1,5 +1,8 @@
# NamedValues: Smart Containers for Simulation Data
+!!! abstract
+ **NamedValues** serve as the deterministic "Source of Truth" for your simulation parameters. By implementing a strict `UNSET`/`SET` lifecycle and **numeric mixins**, these containers ensure data integrity across complex physics models while behaving like native Python numbers in mathematical operations. This guide explores how to use NamedValues and their protected collections to prevent accidental data overrides and maintain a traceable, frozen state for every simulation trial.
+
---
## NamedValue
@@ -10,24 +13,24 @@ In complex simulations, you often need to share a single piece of data (like the
It tracks its own lifecycle using a simple state machine:
-* **`UNSET`**: The container is waiting for data. If you try to read it, the system will raise an error to prevent you from using uninitialized data.
-* **`SET`**: The container has been populated. At this point, it becomes **frozen**. Any accidental attempt to overwrite it will be blocked unless you explicitly use a "force" command.
+- **`UNSET`**: The container is waiting for data. If you try to read it, the system will raise an error to prevent you from using uninitialized data.
+- **`SET`**: The container has been populated. At this point, it becomes **frozen**. Any accidental attempt to overwrite it will be blocked unless you explicitly use a "force" command.
### Why use it?
The primary advantage of `NamedValue` is its **Numeric Mixin** behavior. Even though it is a complex object that tracks names and states, you can use it in your code as if it were a simple float or a NumPy array.
You can do math directly with the container:
-* `result = my_named_value * 5.0`
-* `total = value_a + value_b`
+- `result = my_named_value * 5.0`
+- `total = value_a + value_b`
---
## Working with Collections
In a real project, you'll likely have dozens of parameters. We use specialized collections to manage them:
-* **NamedValueDict**: Best for quick lookups. You can ask for `my_dict["motor_friction"]` and get the container immediately.
-* **NamedValueList**: Useful when you need to iterate through all sampled values to save them to a file or a database.
+- **NamedValueDict**: Best for quick lookups. You can ask for `my_dict["motor_friction"]` and get the container immediately.
+- **NamedValueList**: Useful when you need to iterate through all sampled values to save them to a file or a database.
These collections protect their entries from wayward data updates. If a `NamedValue` with a specific name already exists in the the collection, the value will not be allowed in (without using a force).
diff --git a/docs/user-guides/named_values.py b/docs/user-guides/named_values.py
index ce659b0..877cd8b 100644
--- a/docs/user-guides/named_values.py
+++ b/docs/user-guides/named_values.py
@@ -1,16 +1,18 @@
# ---8<--- [start: basics]
-import process_manager as pm
+import stochas
# 1. Initialize a container with a name and a value
# The state automatically moves to 'SET'
-friction = pm.NamedValue(name=pm.ValueName("joint_friction"), stored_value=0.25)
+friction = stochas.NamedValue(
+ name=stochas.ValueName("joint_friction"), stored_value=0.25
+)
# 2. Use it directly in physics calculations
# No need to call .value - the mixin handles the math
torque_loss = friction * 300
# 3. Manage a group of values
-state_registry = pm.NamedValueDict()
+state_registry = stochas.NamedValueDict()
state_registry.update(friction)
# Access the underlying data safely
@@ -19,7 +21,9 @@
# ---8<--- [start: protection]
# Updating a NamedValue already in the NamedValueDict
-new_friction = pm.NamedValue(name=pm.ValueName("joint_friction"), stored_value=1234)
+new_friction = stochas.NamedValue(
+ name=stochas.ValueName("joint_friction"), stored_value=1234
+)
try:
# "joint_friction" is already in state_registry (fails to update)
diff --git a/docs/user-guides/orchestration.md b/docs/user-guides/orchestration.md
new file mode 100644
index 0000000..9d75426
--- /dev/null
+++ b/docs/user-guides/orchestration.md
@@ -0,0 +1,46 @@
+# StochasBase: The Simulation Conductor
+
+!!! abstract
+ **StochasBase** serves as the central conductor for your simulation lifecycle, synchronizing **Aleatory** randomness with **Epistemic** design choices into a single, deterministic stream. By leveraging "Salted Seed" logic, it ensures that complex Monte Carlo campaigns remain perfectly repeatable across different machines and collaborators. This guide explores the orchestration of model inputs, the mechanics of the "Baked" registry, and the use of manual overrides to isolate variables for high-fidelity debugging and "Golden Case" testing.
+
+---
+
+`StochasBase` is the central "brain" for a simulation trial. It orchestrates the lifecycle of a model by bridging the gap between mathematical uncertainty and deterministic execution.
+
+### Centralized Trial Orchestration
+
+A single instance of `StochasBase` manages [two distinct pillars](https://en.wikipedia.org/wiki/Uncertainty_quantification#Aleatoric_and_epistemic) of simulation inputs:
+
+- **Aleatory Uncertainty (`sample_dist`):** Represents "luck" or noise. These are random draws from probability distributions (Normal, Uniform, etc.) that you cannot control but must account for.
+- **Epistemic Uncertainty (`sample_design`):** Represents "choices." These are tunable parameters (Design Variables) used by optimizers like Optuna or pymoo to find peak performance.
+
+### The Pillars of Repeatability
+
+To ensure that a simulation can be perfectly recreated by a colleague, the orchestrator utilizes a "Salted Seed" logic. Every random draw is a deterministic function of the trial's metadata:
+
+$$Seed_{local} = \mathcal{H}(Seed_{global}, Trial_{num}, Variable_{name})$$
+
+- **Global Seed:** Controls the entire campaign.
+- **Trial Number:** Ensures trial 10 is different from trial 11.
+- **Variable Name:** Ensures "stiffness" doesn't get the same random value as "damping."
+
+---
+
+## The "Baked" Registry (named)
+
+While `StochasBase` is designed to automate randomness and optimization, you often need to bypass the math to test a specific "Golden Case" or debug a known failure point. Overrides allow you to inject fixed values into the Baked Registry before the simulation begins.
+
+The orchestrator follows a strict priority sequence when a variable is requested:
+
+1. **Registry Check:** It looks in the `named` dictionary. If a value exists, it returns it immediately.
+2. **Logic Execution:** If the registry is empty, it proceeds to draw from a distribution or ask an optimizer for a suggestion.
+
+By using `with_overrides()`, you populate the registry early, effectively "locking" those variables for the duration of the trial.
+
+---
+
+## Quick Implementation
+
+```python
+--8<-- "docs/user-guides/orchestration.py"
+```
diff --git a/docs/user-guides/orchestration.py b/docs/user-guides/orchestration.py
new file mode 100644
index 0000000..d4466b1
--- /dev/null
+++ b/docs/user-guides/orchestration.py
@@ -0,0 +1,39 @@
+import numpy as np
+
+import stochas
+
+
+class MyModel(stochas.StochasBase):
+ """Put your logic for running your model here!"""
+
+
+overrides = stochas.NamedValueDict()
+overrides.update(
+ stochas.NamedValue(
+ name=stochas.ValueName("overridden_value"), stored_value=np.array([3.14])
+ )
+)
+
+model = MyModel().with_seed(42).with_trial_num(1).with_overrides(overrides)
+
+# 1. Random draw
+noise = model.sample_dist(
+ stochas.NormalDistribution(
+ name=stochas.DistName("sensor_noise"), nominal=0, mu=0, sigma=0.1
+ )
+)
+
+# 2. Tunable parameter
+width = model.sample_design(
+ stochas.DesignFloat(
+ name=stochas.ValueName("base_width"), low=1.0, high=5.0, stored_value=2.5
+ )
+)
+
+# Both are now registered in model.named for later analysis.
+
+# fails to update named value dict! overridden_value is already in the named value dict
+overridden_value = model.sample_dist(
+ stochas.PoissonDistribution(name=stochas.DistName("overridden_value"), lam=4)
+)
+assert overridden_value == np.array([3.14]) # this check passes!
diff --git a/mkdocs.yml b/mkdocs.yml
index 36992fa..273c37b 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -1,9 +1,9 @@
-site_name: Process Manager
-site_url: https://talbotknighton.github.io/process_manager/
+site_name: stochas
+site_url: https://hydrowelder.github.io/stochas/
site_author: Talbot Knighton and David Gable
copyright: Copyright © 2026 Talbot Knighton and David Gable
-repo_url: https://github.com/TalbotKnighton/process_manager
-repo_name: process_manager
+repo_url: https://github.com/Hydrowelder/stochas
+repo_name: stochas
remote_branch: gh-pages
remote_name: origin
@@ -17,26 +17,31 @@ nav:
- User Guides:
- Named Values: user-guides/named-values.md
- Distributions: user-guides/distributions.md
+ - Design Values: user-guides/design-values.md
+ - Orchestration: user-guides/orchestration.md
- Code Reference: reference/
theme:
name: material
+ logo: assets/main-logo.svg
+ favicon: assets/main-logo.svg
+ font: false
palette:
- media: "(prefers-color-scheme: light)"
scheme: default
- primary: pink
- accent: blue
+ primary: custom
+ accent: custom
toggle:
- icon: material/weather-sunny
+ icon: material/lightbulb-on
name: Switch to dark mode
- media: "(prefers-color-scheme: dark)"
scheme: slate
- primary: pink
- accent: blue
+ primary: custom
+ accent: custom
toggle:
- icon: material/weather-night
+ icon: material/lightbulb-outline
name: Switch to light mode
features:
@@ -96,7 +101,7 @@ plugins:
inheritance_diagram_direction: TD
show_inheritance_diagram: true
show_attribute_values: true
- signature_crossrefs: true
+ # signature_crossrefs: true
extensions:
- pydantic: { schema: true }
inventories:
@@ -112,6 +117,8 @@ markdown_extensions:
- attr_list
- md_in_html
- def_list
+ - pymdownx.arithmatex:
+ generic: true
- pymdownx.tasklist:
custom_checkbox: true
- toc:
@@ -121,6 +128,7 @@ markdown_extensions:
line_spans: __span
pygments_lang_class: true
auto_title: true
+ linenums: true
- pymdownx.inlinehilite
- pymdownx.details
- pymdownx.snippets
@@ -144,6 +152,13 @@ markdown_extensions:
- pymdownx.tilde
extra_javascript:
+ - javascripts/katex.js
+ - https://unpkg.com/katex@0/dist/katex.min.js
+ - https://unpkg.com/katex@0/dist/contrib/auto-render.min.js
- https://unpkg.com/mermaid@10.9.0/dist/mermaid.min.js
- https://unpkg.com/tablesort@5.3.0/dist/tablesort.min.js
- javascripts/tablesort.js
+
+extra_css:
+ - css/extra.css
+ - https://unpkg.com/katex@0/dist/katex.min.css
diff --git a/pyproject.toml b/pyproject.toml
index f85000b..760935c 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -1,21 +1,45 @@
[build-system]
-requires = ["setuptools>=61", "wheel"]
-build-backend = "setuptools.build_meta"
+requires = ["hatchling", "hatch-vcs"]
+build-backend = "hatchling.build"
[project]
-name = "process-manager"
-version = "0.1.0"
-description = "Add your description here"
+name = "stochas"
+dynamic = ["version"]
+description = "stochas is a Python framework built to handle the complexity of Monte Carlo simulations, parametric studies, and probabilistic modeling."
readme = "README.md"
-license-files = ["LICENSE"]
requires-python = ">=3.12"
dependencies = [
"numpy>=2.4.2",
"numpydantic>=1.7.0",
+ "optuna>=4.8.0",
"pydantic>=2.12.5",
+ "pymoo>=0.6.1.6",
"scipy>=1.17.0",
]
+
+classifiers = [
+ "Development Status :: 4 - Beta",
+ "Intended Audience :: Science/Research",
+ "Topic :: Scientific/Engineering :: Physics",
+ "Topic :: Scientific/Engineering :: Visualization",
+ "License :: OSI Approved :: Apache Software License",
+ "Programming Language :: Python :: 3.12",
+ "Programming Language :: Python :: 3.13",
+ "Programming Language :: Python :: 3.14",
+]
+authors = [{ name = "David Gable", email = "dave.a.gable@gmail.com" }]
+maintainers = [{ name = "David Gable", email = "dave.a.gable@gmail.com" }]
+license = { text = "Apache-2.0" }
+
+
+[tool.hatch.version]
+source = "vcs"
+fallback-version = "0.0.0"
+
+[tool.hatch.build.targets.wheel]
+packages = ["src/stochas"]
+
[tool.ruff]
exclude = ["typings", "scripts/templating/sensor_template.py"]
@@ -59,7 +83,7 @@ ignore = [
[tool.pyright]
stubPath = "typings"
-venvPath = "."
+venvPath = ".."
venv = ".venv"
ignore = ["typings"]
@@ -82,3 +106,10 @@ dev = [
"scipy-stubs>=1.17.0.2",
"tabulate>=0.9.0",
]
+
+[project.urls]
+Homepage = "https://github.com/Hydrowelder/stochas"
+Documentation = "https://hydrowelder.github.io/stochas/"
+Repository = "https://github.com/Hydrowelder/stochas"
+Issues = "https://github.com/Hydrowelder/stochas/issues"
+Discussions = "https://github.com/Hydrowelder/stochas/discussions"
diff --git a/requirements.txt b/requirements.txt
index dc11f1e..43ec5b1 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -338,7 +338,7 @@ numpy==2.4.2 \
# numpy-typing-compat
# numpydantic
# optype
- # process-manager
+ # stochas
# scipy
numpy-typing-compat==20251206.2.4 \
--hash=sha256:59882d23aaff054a2536da80564012cdce33487657be4d79c5925bb8705fcabc \
@@ -347,7 +347,7 @@ numpy-typing-compat==20251206.2.4 \
numpydantic==1.7.0 \
--hash=sha256:268285bee026d9dfdf23efeee13f60c3b75d47de2ffdf2e58b4f0c17a6824e3b \
--hash=sha256:81314ed00423efa954a711a48003dba5382156e899f677f405ce043f5296b090
- # via process-manager
+ # via stochas
optype==0.15.0 \
--hash=sha256:457d6ca9e7da19967ec16d42bdf94e240b33b5d70a56fbbf5b427e5ea39cf41e \
--hash=sha256:caba40ece9ea39b499fa76c036a82e0d452a432dd4dd3e8e0d30892be2e8c76c
@@ -381,7 +381,7 @@ pydantic==2.12.5 \
--hash=sha256:e561593fccf61e8a20fc46dfc2dfe075b8be7d0188df33f221ad1f0139180f9d
# via
# numpydantic
- # process-manager
+ # stochas
pydantic-core==2.41.5 \
--hash=sha256:0177272f88ab8312479336e1d777f6b124537d47f2123f89cb37e0accea97f90 \
--hash=sha256:01a3d0ab748ee531f4ea6c3e48ad9dac84ddba4b0d82291f87248f2f9de8d740 \
@@ -557,7 +557,7 @@ scipy==1.17.0 \
--hash=sha256:f7df7941d71314e60a481e02d5ebcb3f0185b8d799c70d03d8258f6c80f3d467 \
--hash=sha256:f9eb55bb97d00f8b7ab95cb64f873eb0bf54d9446264d9f3609130381233483f \
--hash=sha256:fe508b5690e9eaaa9467fc047f833af58f1152ae51a0d0aed67aa5801f4dd7d6
- # via process-manager
+ # via stochas
scipy-stubs==1.17.0.2 \
--hash=sha256:3981bd7fa4c189a8493307afadaee1a830d9a0de8e3ae2f4603f192b6260ef2a \
--hash=sha256:99d1aa75b7d72a7ee36a68d18bcf1149f62ab577bbd1236c65c471b3b465d824
diff --git a/src/process_manager/__init__.py b/src/stochas/__init__.py
similarity index 71%
rename from src/process_manager/__init__.py
rename to src/stochas/__init__.py
index aadb30e..857bfe9 100644
--- a/src/process_manager/__init__.py
+++ b/src/stochas/__init__.py
@@ -1,8 +1,19 @@
+from .base import StochasBase
from .base_collections import BaseDict, BaseList
+from .design_variable import (
+ AnyDesignValue,
+ DesignBool,
+ DesignCategorical,
+ DesignFloat,
+ DesignInt,
+ DesignValueDict,
+ DesignValueList,
+)
from .distribution import (
NOMINAL_TRIAL_NUM,
BernoulliDistribution,
CategoricalDistribution,
+ DiscreteUniformDistribution,
Dist,
DistName,
Distribution,
@@ -14,6 +25,7 @@
NormalDistribution,
PermutationDistribution,
PoissonDistribution,
+ RayleighDistribution,
TriangularDistribution,
TruncatedNormalDistribution,
UniformDistribution,
@@ -29,10 +41,18 @@
__all__ = [
"NOMINAL_TRIAL_NUM",
+ "AnyDesignValue",
"BaseDict",
"BaseList",
"BernoulliDistribution",
"CategoricalDistribution",
+ "DesignBool",
+ "DesignCategorical",
+ "DesignFloat",
+ "DesignInt",
+ "DesignValueDict",
+ "DesignValueList",
+ "DiscreteUniformDistribution",
"Dist",
"DistName",
"DistType",
@@ -48,6 +68,8 @@
"NormalDistribution",
"PermutationDistribution",
"PoissonDistribution",
+ "RayleighDistribution",
+ "StochasBase",
"TriangularDistribution",
"TruncatedNormalDistribution",
"UniformDistribution",
diff --git a/src/stochas/base.py b/src/stochas/base.py
new file mode 100644
index 0000000..cb63dee
--- /dev/null
+++ b/src/stochas/base.py
@@ -0,0 +1,167 @@
+import logging
+from typing import Any, Self, TypeVar, overload
+
+from numpydantic import NDArray
+from pydantic import BaseModel, Field, SerializeAsAny
+
+from stochas.design_variable import (
+ AnyDesignValue,
+ DesignBool,
+ DesignCategorical,
+ DesignFloat,
+ DesignInt,
+ DesignValueDict,
+)
+from stochas.distribution import NOMINAL_TRIAL_NUM, Dist, DistributionDict
+from stochas.named_value import NamedValue, NamedValueDict
+
+logger = logging.getLogger(__name__)
+
+T = TypeVar("T")
+
+
+class StochasBase(BaseModel):
+ trial_num: int = NOMINAL_TRIAL_NUM
+ """Trial number identified for this instance of the model."""
+
+ seed: int | None = None
+ """Campaign seed for calculating random numbers."""
+
+ design: DesignValueDict = Field(default_factory=DesignValueDict)
+ """Registry of parameters for hyperparameter tuning."""
+
+ dists: DistributionDict = Field(default_factory=DistributionDict)
+ """Random distributions used to generate the model."""
+
+ named: SerializeAsAny[NamedValueDict[NDArray]] = Field(
+ default_factory=NamedValueDict[NDArray]
+ )
+ """Final 'baked' values from a random draw, global override, or design study."""
+
+ def sample_dist(
+ self,
+ dist: Dist,
+ size: int = 1,
+ force: bool = False,
+ warn: bool = True,
+ ) -> NamedValue[NDArray]:
+ """
+ Sets the seed and trial number of the distribution, sample, registers it and the sampled value to the model, and returns the named value.
+
+ If the NamedValue is already registered, the registered named value is returned.
+
+ Args:
+ dist (Dist): Distribution to sample and register.
+ size (int, optional): Number of samples to take. Will be embedded in the returned NamedValue. Defaults to 1.
+ force (bool, optional): Force the sampled value into the NamedValueDict if it already exists. Defaults to False.
+ warn (bool, optional): Whether or not to warn if there is a conflict while forcing. Defaults to True.
+
+ Returns:
+ NamedValue[NDArray]: NamedValue containing the random draw.
+
+ """
+ dist.with_seed(self.seed).with_trial_num(self.trial_num)
+
+ if dist.name not in self.dists:
+ self.dists.update(dist)
+ elif force:
+ self.dists.force_update(dist)
+
+ nv = dist.sample_to_named_value(size=size)
+
+ if nv in self.named and not force:
+ # defined with global override or already sampled
+ if warn:
+ logger.warning(
+ f"NamedValue {nv.name} already registered. Returning it instead of the sampled value."
+ )
+ return self.named[nv.name]
+ elif nv in self.named and force:
+ # defined with global override but forced to update
+ if warn:
+ logger.warning(
+ f"NamedValue {nv.name} already registered. Force setting it to the new value in the registry.",
+ )
+ self.named.force_update(nv, warn=False)
+ else:
+ # standard random draw
+ self.named.update(nv)
+ return nv
+
+ @overload
+ def sample_design(
+ self, dv: DesignFloat, force: bool = False, warn: bool = True
+ ) -> float: ...
+
+ @overload
+ def sample_design(
+ self, dv: DesignInt, force: bool = False, warn: bool = True
+ ) -> int: ...
+
+ @overload
+ def sample_design(
+ self, dv: DesignBool, force: bool = False, warn: bool = True
+ ) -> bool: ...
+
+ @overload
+ def sample_design(
+ self, dv: DesignCategorical[T], force: bool = False, warn: bool = True
+ ) -> T: ...
+
+ def sample_design(
+ self, dv: AnyDesignValue, force: bool = False, warn: bool = True
+ ) -> Any:
+ self.design[dv.name] = dv
+
+ if dv.name in self.named and not force:
+ if warn:
+ logger.info(f"Using override for design variable: {dv.name}")
+ val = self.named[dv.name].value
+ return val.item() if hasattr(val, "item") else val
+
+ self.named.update(dv)
+ return dv.value
+
+ def with_overrides(self, overrides: NamedValueDict[NDArray]) -> Self:
+ """
+ Sets the NamedValueDict to the provided override.
+
+ This is useful for manually setting some named values to be used.
+ """
+ self.named = overrides
+ return self
+
+ def with_seed(self, seed: int | None = None) -> Self:
+ """
+ Sets the seed to the provided value.
+
+ This is useful for initializaing the model.
+ """
+ self.seed = seed
+ for _, dist in self.dists.items():
+ dist.with_seed(seed)
+ return self
+
+ def with_trial_num(self, trial_num: int) -> Self:
+ """
+ Sets the trial_num to the provided value.
+
+ This is useful for initializaing the model.
+ """
+ self.trial_num = trial_num
+ for _, dist in self.dists.items():
+ dist.with_trial_num(trial_num)
+ return self
+
+ def with_override(self, override: NamedValueDict[NDArray]) -> Self:
+ """
+ Sets the NamedValueDict to the provided override.
+
+ This is useful for manually setting some named values to be used.
+ """
+ self.named = override
+ return self
+
+ @property
+ def is_nominal(self) -> bool:
+ return self.trial_num == NOMINAL_TRIAL_NUM
diff --git a/src/process_manager/base_collections.py b/src/stochas/base_collections.py
similarity index 92%
rename from src/process_manager/base_collections.py
rename to src/stochas/base_collections.py
index 8f6594c..3d99890 100644
--- a/src/process_manager/base_collections.py
+++ b/src/stochas/base_collections.py
@@ -7,6 +7,8 @@
import numpy as np
from pydantic import Field, RootModel
+from stochas.utils import _reconstruct_obj
+
logger = logging.getLogger(__name__)
__all__ = ["BaseDict", "BaseList"]
@@ -15,6 +17,12 @@
class BaseDict[T](RootModel[dict[str, T]]):
root: dict[str, T] = Field(default_factory=dict)
+ def __reduce__(self):
+ return (
+ _reconstruct_obj,
+ (self.__class__.__module__, self.__class__.__name__, self.model_dump()),
+ )
+
def __getitem__(self, key: str) -> T:
"""Get an item in the dictionary with the specified key."""
if key not in self.root:
@@ -87,6 +95,12 @@ def force_update_many(self, values: Iterable[T], warn: bool = True) -> None:
class BaseList[T](RootModel[list[T]]):
root: list[T] = Field(default_factory=list)
+ def __reduce__(self):
+ return (
+ _reconstruct_obj,
+ (self.__class__.__module__, self.__class__.__name__, self.model_dump()),
+ )
+
def __array__(self, dtype=None, copy=None) -> np.ndarray:
return np.array(self.root, dtype=dtype, copy=copy)
@@ -141,7 +155,7 @@ def find_by_name(self, name: str) -> T:
if __name__ == "__main__":
from typing import Any
- from process_manager import NamedValue, NamedValueDict, NamedValueList, ValueName
+ from stochas import NamedValue, NamedValueDict, NamedValueList, ValueName
name = NamedValue[str](name=ValueName("name"), stored_value="john")
age = NamedValue[int](name=ValueName("age"), stored_value=1)
diff --git a/src/stochas/design_variable.py b/src/stochas/design_variable.py
new file mode 100644
index 0000000..f7a9b0d
--- /dev/null
+++ b/src/stochas/design_variable.py
@@ -0,0 +1,231 @@
+from __future__ import annotations
+
+import logging
+from abc import ABC, abstractmethod
+from collections.abc import Sequence
+from typing import Annotated, Any, Literal, Self, cast
+
+import numpy as np
+import optuna
+from pydantic import Field, model_validator
+from pymoo.core.variable import Binary, Choice, Integer, Real
+
+from stochas.base_collections import BaseDict, BaseList
+from stochas.named_value import NamedValue, ValueName
+
+__all__ = [
+ "DesignBool",
+ "DesignCategorical",
+ "DesignFloat",
+ "DesignInt",
+ "DesignValueDict",
+ "DesignValueList",
+]
+
+logger = logging.getLogger(__name__)
+
+
+class OptimizationSuggestor(ABC):
+ @abstractmethod
+ def to_optuna(self, trial: optuna.Trial) -> Any:
+ pass
+
+ @abstractmethod
+ def to_pymoo(self) -> Any: ...
+
+ @abstractmethod
+ def refine(self, factor: float, best_params: dict[str, Any]) -> None:
+ pass
+
+
+class DesignBool(NamedValue[bool], OptimizationSuggestor):
+ """A specific 0/1 toggle, useful for enabling/disabling branches."""
+
+ type: Literal["binary"] = "binary"
+
+ def suggest(self, trial: optuna.Trial) -> bool:
+ return trial.suggest_categorical(self.name, [True, False])
+
+ def to_pymoo(self) -> Binary:
+ return Binary()
+
+ def refine(self, factor: float, best_params: dict[str, Any]):
+ logger.debug(f"Refinement not applicable for binary '{self.name}'.")
+
+
+class DesignCategorical[T](NamedValue[T], OptimizationSuggestor):
+ """A NamedValue that represents a categorical design parameter to be optimized."""
+
+ type: Literal["categorical"] = "categorical"
+
+ choices: Sequence[T]
+ """For categorical search (e.g., choices=['stiff', 'soft'])."""
+
+ def to_optuna(self, trial: optuna.Trial):
+ return trial.suggest_categorical(
+ name=self.name,
+ choices=self.choices, # type: ignore
+ )
+
+ def to_pymoo(self) -> Choice:
+ return Choice(options=np.array(self.choices, dtype=object))
+
+ def refine(self, factor: float, best_params: dict[str, Any]):
+ logger.debug(f"Skipping refinement for categorical '{self.name}'.")
+
+
+class DesignFloat(NamedValue[float], OptimizationSuggestor):
+ """
+ A NamedValue that represents a floating point design parameter to be optimized.
+
+ Contains bounds required for search space discovery.
+ """
+
+ type: Literal["float"] = "float"
+
+ low: float
+ """Lower bound for hyperparameter tuning."""
+
+ high: float
+ """Upper bound for hyperparameter tuning."""
+
+ log: bool = False
+ """Use support for log-scale search (useful for learning rates or stiffness)."""
+
+ step: float | None = None
+ """Discretize the search space (e.g., step=0.5)."""
+
+ @model_validator(mode="after")
+ def validate_bounds(self) -> Self:
+ if self.high <= self.low:
+ msg = f"DesignFloat '{self.name}': high must be greater than low"
+ logger.error(msg)
+ raise ValueError(msg)
+ if self.log and self.low <= 0:
+ msg = f"DesignFloat '{self.name}': low must be greater than 0 when log=True"
+ logger.error(msg)
+ raise ValueError(msg)
+ if self.step is not None and self.step <= 0:
+ msg = f"DesignFloat '{self.name}': step must be greater than 0"
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ def to_optuna(self, trial: optuna.Trial):
+ return trial.suggest_float(
+ name=self.name,
+ low=self.low,
+ high=self.high,
+ log=self.log,
+ step=self.step,
+ )
+
+ def to_pymoo(self) -> Real:
+ return Real(bounds=(self.low, self.high))
+
+ def refine(self, factor: float, best_params: dict[str, Any]):
+ best_val = cast(float, best_params[self.name])
+ orig_range = self.high - self.low
+ new_half_range = (orig_range * factor) / 2
+
+ self.low = max(self.low, best_val - new_half_range)
+ self.high = min(self.high, best_val + new_half_range)
+
+ logger.debug(f"Refined float '{self.name}': [{self.low:.4f}, {self.high:.4f}]")
+
+
+class DesignInt(NamedValue[int], OptimizationSuggestor):
+ """
+ A NamedValue representing an integer design parameter (e.g., number of solver iterations).
+ """
+
+ type: Literal["int"] = "int"
+
+ low: int
+ """Lower bound (inclusive)."""
+
+ high: int
+ """Upper bound (inclusive)."""
+
+ step: int = 1
+ """Spacing between values."""
+
+ log: bool = False
+ """Whether to sample from a log-scale (useful for orders of magnitude)."""
+
+ @model_validator(mode="after")
+ def validate_bounds(self) -> Self:
+ if self.high <= self.low:
+ msg = f"DesignInt '{self.name}': high must be greater than low"
+ logger.error(msg)
+ raise ValueError(msg)
+ if self.log and self.low <= 0:
+ msg = f"DesignInt '{self.name}': low must be greater than 0 when log=True"
+ logger.error(msg)
+ raise ValueError(msg)
+ if self.step <= 0:
+ msg = f"DesignInt '{self.name}': step must be greater than 0"
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ def to_optuna(self, trial: optuna.Trial) -> int:
+ return trial.suggest_int(
+ name=self.name,
+ low=self.low,
+ high=self.high,
+ step=self.step,
+ log=self.log,
+ )
+
+ def to_pymoo(self) -> Integer:
+ return Integer(bounds=(self.low, self.high))
+
+ def refine(self, factor: float, best_params: dict[str, Any]):
+ best_val = cast(float, best_params[self.name])
+ orig_range = self.high - self.low
+ new_half_range = (orig_range * factor) / 2
+
+ self.low = int(np.floor(max(self.low, best_val - new_half_range)))
+ self.high = int(np.ceil(min(self.high, best_val + new_half_range)))
+
+ logger.debug(f"Refined int '{self.name}': [{self.low:.4f}, {self.high:.4f}]")
+
+
+AnyDesignValue = Annotated[
+ DesignFloat | DesignCategorical | DesignInt | DesignBool,
+ Field(discriminator="type"),
+]
+
+
+class DesignValueDict(BaseDict[AnyDesignValue]):
+ """Dictionary specifically for sampled results."""
+
+ def __contains__(self, key: object) -> bool:
+ if isinstance(key, NamedValue):
+ key = key.name
+ return super().__contains__(key=key)
+
+ def get_value(self, name: ValueName | str) -> Any:
+ """Gets the NamedValue value of a key."""
+ return self[name].value
+
+ def get_raw_value(self, name: ValueName | str) -> Any | None:
+ """Gets the NamedValue raw value. This includes None if the value has not yet been set."""
+ return self[name].stored_value
+
+ @property
+ def named_value_list(self) -> DesignValueList:
+ """Converts the DesignValueDict to a DesignValueList."""
+ return DesignValueList(list(self.values()))
+
+
+class DesignValueList(BaseList[AnyDesignValue]):
+ """List specifically for sampled results."""
+
+ @property
+ def to_named_value_dict(self) -> DesignValueDict:
+ """Converts the DesignValueList to a DesignValueDict."""
+ d = DesignValueDict()
+ d.update_many(self.root)
+ return d
diff --git a/src/process_manager/distribution.py b/src/stochas/distribution.py
similarity index 86%
rename from src/process_manager/distribution.py
rename to src/stochas/distribution.py
index 71d7373..9a59682 100644
--- a/src/process_manager/distribution.py
+++ b/src/stochas/distribution.py
@@ -26,8 +26,8 @@
model_validator,
)
-from process_manager.base_collections import BaseDict, BaseList
-from process_manager.named_value import NamedValue, NamedValueDict, ValueName
+from stochas.base_collections import BaseDict, BaseList
+from stochas.named_value import NamedValue, NamedValueDict, ValueName
if TYPE_CHECKING:
from scipy.stats.distributions import rv_continuous, rv_discrete, rv_frozen
@@ -52,6 +52,7 @@
"NormalDistribution",
"PermutationDistribution",
"PoissonDistribution",
+ "RayleighDistribution",
"TriangularDistribution",
"TruncatedNormalDistribution",
"UniformDistribution",
@@ -71,6 +72,9 @@ class DistType(StrEnum):
UNIFORM = "uniform"
"""Uniform distribution."""
+ DISCRETE_UNIFORM = "discrete_uniform"
+ """Discrete uniform distribution."""
+
CATEGORICAL = "categorical"
"""Categorical distribution."""
@@ -92,6 +96,9 @@ class DistType(StrEnum):
EXPONENTIAL = "exponential"
"""Exponential distribution."""
+ RAYLEIGH = "rayleigh"
+ """Rayleigh distribution."""
+
BERNOULLI = "bernoulli"
"""Bernoulli distribution."""
@@ -293,7 +300,7 @@ class NormalDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Normal_distribution)
Note:
-  +
+ +
+
+
+
+
+  +
+
+
+
+
+  +
+ +
+  """
@@ -355,7 +362,7 @@ class UniformDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Continuous_uniform_distribution)
Note:
-
"""
@@ -355,7 +362,7 @@ class UniformDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Continuous_uniform_distribution)
Note:
-  +
+  """
@@ -403,6 +410,70 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
return self._scipy.ppf(q)
+class DiscreteUniformDistribution(Distribution[int]):
+ """
+ Represent a distribution where every integer in a range is equally likely.
+
+ Use this for discrete counts like number of objects, gear teeth, or
+ array indices where you need equal probability across the whole range.
+
+ Examples:
+ ```python
+ dist = DiscreteUniformDistribution(name=name, low=-1, high=2)
+ ```
+
+ References:
+ 1. [NumPy](https://numpy.org/doc/2.1/reference/random/generated/numpy.random.Generator.integers.html)
+ 2. [SciPy](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.randint.html)
+ 3. [Wikipedia](https://en.wikipedia.org/wiki/Discrete_uniform_distribution)
+
+ Note:
+
"""
@@ -403,6 +410,70 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
return self._scipy.ppf(q)
+class DiscreteUniformDistribution(Distribution[int]):
+ """
+ Represent a distribution where every integer in a range is equally likely.
+
+ Use this for discrete counts like number of objects, gear teeth, or
+ array indices where you need equal probability across the whole range.
+
+ Examples:
+ ```python
+ dist = DiscreteUniformDistribution(name=name, low=-1, high=2)
+ ```
+
+ References:
+ 1. [NumPy](https://numpy.org/doc/2.1/reference/random/generated/numpy.random.Generator.integers.html)
+ 2. [SciPy](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.randint.html)
+ 3. [Wikipedia](https://en.wikipedia.org/wiki/Discrete_uniform_distribution)
+
+ Note:
+ 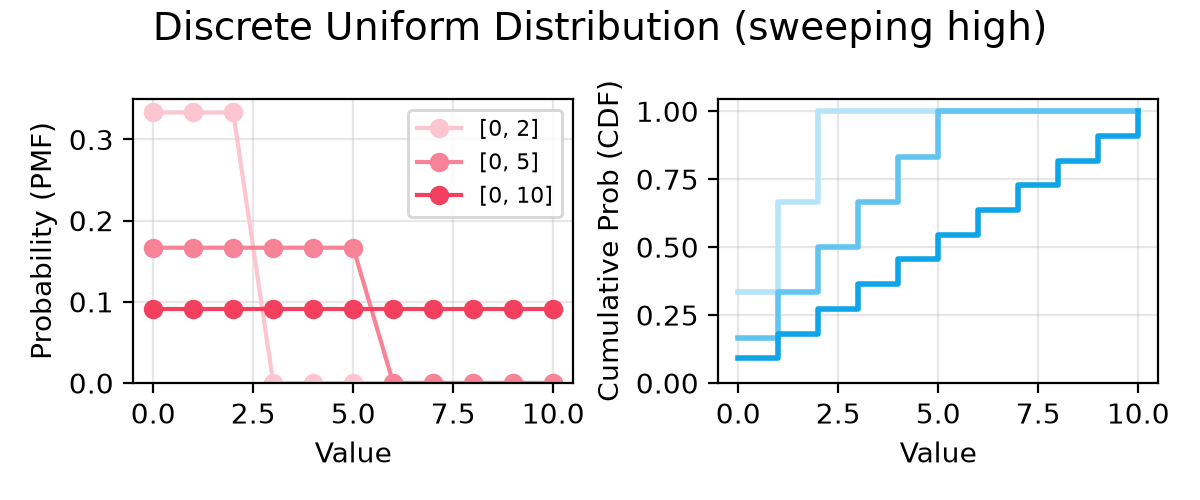 +
+ """
+
+ low: int
+ high: int
+
+ _scipy: rv_discrete = PrivateAttr()
+
+ dist_type: Literal[DistType.DISCRETE_UNIFORM] = DistType.DISCRETE_UNIFORM
+
+ @model_validator(mode="after")
+ def validate_low_high(self) -> Self:
+ if self.high <= self.low:
+ msg = f"Distribution {self.name}: high must be greater than low"
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ @model_validator(mode="after")
+ def validate_scipy(self) -> Self:
+ self._scipy = stats.randint(low=self.low, high=self.high + 1) # pyright: ignore[reportAttributeAccessIssue]
+ return self
+
+ def draw(self, size: int = 1) -> np.ndarray:
+ return self.rng.integers(low=self.low, high=self.high, size=size, endpoint=True)
+
+ @property
+ def is_continuous(self) -> Literal[False]:
+ return False
+
+ def pdf(self, x: Any) -> float | NDArray[Any, float]:
+ logger.warning(DISCRETE_MSG)
+ return self.pmf(k=x)
+
+ def pmf(self, k: int | np.ndarray) -> float | np.ndarray:
+ """Probability Mass Function."""
+ return self._scipy.pmf(k)
+
+ def cdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.cdf(x)
+
+ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.ppf(q)
+
+
class CategoricalDistribution[T](Distribution[T]):
"""
Represent a discrete distribution over a fixed set of named choices.
@@ -428,7 +499,7 @@ class Material(StrEnum):
3. [Wikipedia](https://en.wikipedia.org/wiki/Categorical_distribution)
Note:
-
+
+ """
+
+ low: int
+ high: int
+
+ _scipy: rv_discrete = PrivateAttr()
+
+ dist_type: Literal[DistType.DISCRETE_UNIFORM] = DistType.DISCRETE_UNIFORM
+
+ @model_validator(mode="after")
+ def validate_low_high(self) -> Self:
+ if self.high <= self.low:
+ msg = f"Distribution {self.name}: high must be greater than low"
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ @model_validator(mode="after")
+ def validate_scipy(self) -> Self:
+ self._scipy = stats.randint(low=self.low, high=self.high + 1) # pyright: ignore[reportAttributeAccessIssue]
+ return self
+
+ def draw(self, size: int = 1) -> np.ndarray:
+ return self.rng.integers(low=self.low, high=self.high, size=size, endpoint=True)
+
+ @property
+ def is_continuous(self) -> Literal[False]:
+ return False
+
+ def pdf(self, x: Any) -> float | NDArray[Any, float]:
+ logger.warning(DISCRETE_MSG)
+ return self.pmf(k=x)
+
+ def pmf(self, k: int | np.ndarray) -> float | np.ndarray:
+ """Probability Mass Function."""
+ return self._scipy.pmf(k)
+
+ def cdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.cdf(x)
+
+ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.ppf(q)
+
+
class CategoricalDistribution[T](Distribution[T]):
"""
Represent a discrete distribution over a fixed set of named choices.
@@ -428,7 +499,7 @@ class Material(StrEnum):
3. [Wikipedia](https://en.wikipedia.org/wiki/Categorical_distribution)
Note:
- 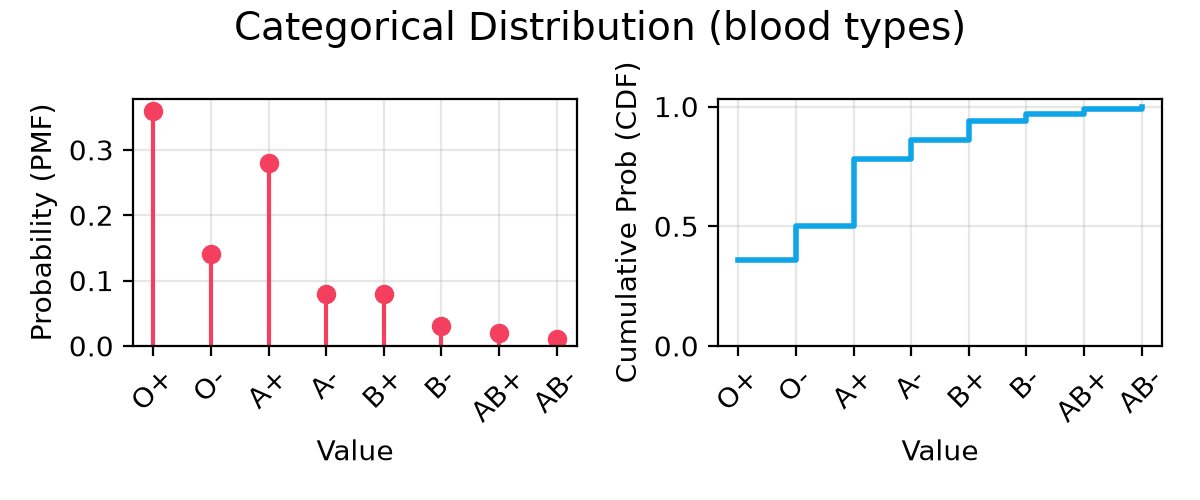 +
+ 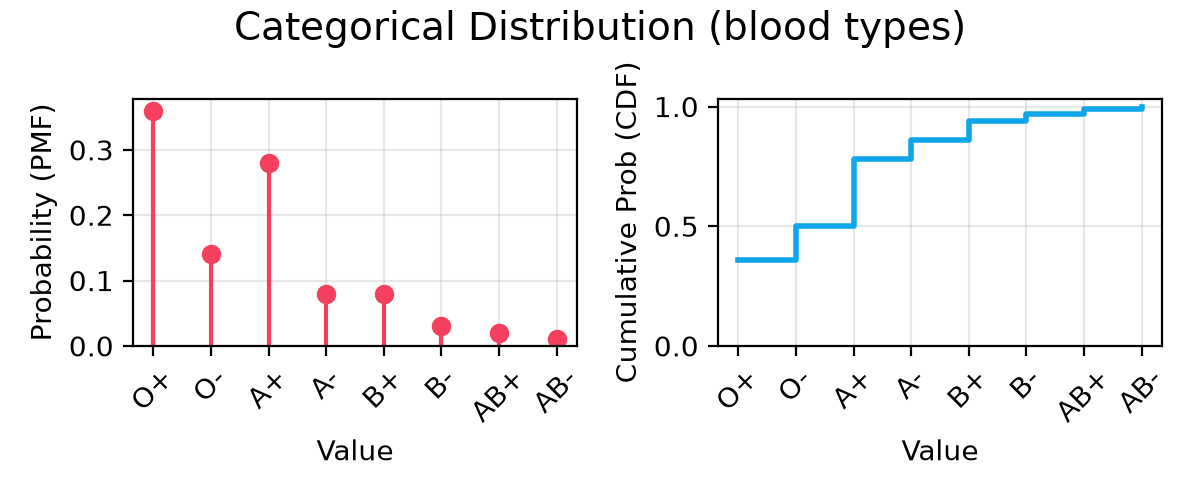 """
@@ -572,7 +643,7 @@ class TriangularDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Triangular_distribution)
Note:
-
"""
@@ -572,7 +643,7 @@ class TriangularDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Triangular_distribution)
Note:
- 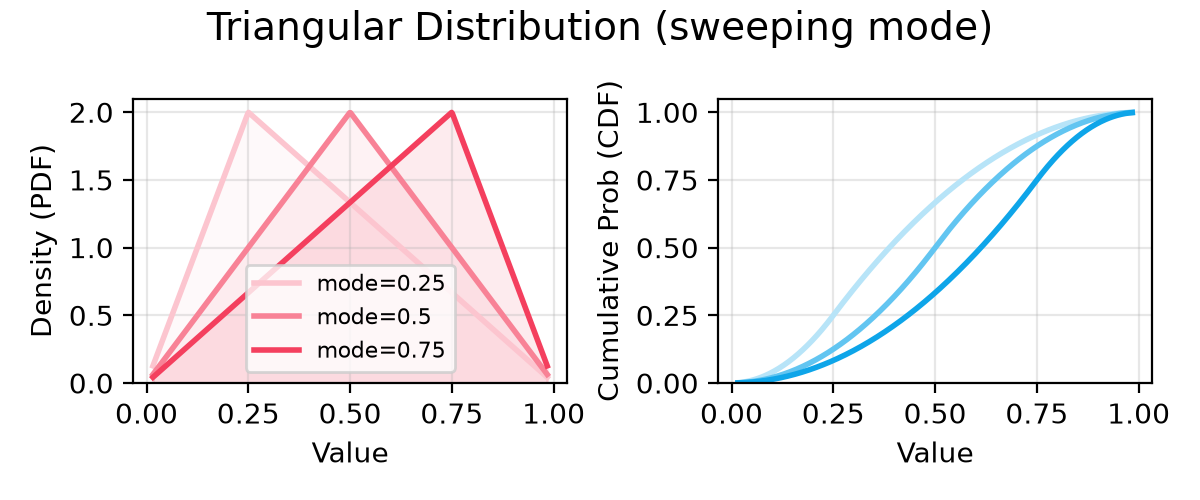 +
+  """
@@ -641,7 +712,7 @@ class TruncatedNormalDistribution(Distribution[float]):
2. [Wikipedia](https://en.wikipedia.org/wiki/Truncated_normal_distribution)
Note:
-
"""
@@ -641,7 +712,7 @@ class TruncatedNormalDistribution(Distribution[float]):
2. [Wikipedia](https://en.wikipedia.org/wiki/Truncated_normal_distribution)
Note:
-  +
+  """
@@ -705,7 +776,7 @@ class LogNormalDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Log-normal_distribution)
Note:
-
"""
@@ -705,7 +776,7 @@ class LogNormalDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Log-normal_distribution)
Note:
-  +
+  """
@@ -759,7 +830,7 @@ class PoissonDistribution(Distribution[int]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Poisson_distribution)
Note:
-
"""
@@ -759,7 +830,7 @@ class PoissonDistribution(Distribution[int]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Poisson_distribution)
Note:
-  +
+  """
@@ -817,7 +888,7 @@ class ExponentialDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Exponential_distribution)
Note:
-
"""
@@ -817,7 +888,7 @@ class ExponentialDistribution(Distribution[float]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Exponential_distribution)
Note:
-  +
+  """
@@ -850,6 +921,65 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
return self._scipy.ppf(q)
+class RayleighDistribution(Distribution[float]):
+ """
+ Represent the magnitude of a 2D vector whose components are independent, identically distributed Normal variables.
+
+ Commonly used to model wind speed, signal amplitude noise, or radial positioning error where the underlying x and y errors are independent Gaussians.
+
+ Examples:
+ ```python
+ # Modeling radial placement error of an object on a table
+ dist = RayleighDistribution(name="placement_error", scale=0.02)
+ ```
+
+ References:
+ 1. [NumPy](https://numpy.org/doc/stable/reference/random/generated/numpy.random.rayleigh.html)
+ 2. [SciPy](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rayleigh.html)
+ 3. [Wikipedia](https://en.wikipedia.org/wiki/Rayleigh_distribution)
+
+ Note:
+
"""
@@ -850,6 +921,65 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
return self._scipy.ppf(q)
+class RayleighDistribution(Distribution[float]):
+ """
+ Represent the magnitude of a 2D vector whose components are independent, identically distributed Normal variables.
+
+ Commonly used to model wind speed, signal amplitude noise, or radial positioning error where the underlying x and y errors are independent Gaussians.
+
+ Examples:
+ ```python
+ # Modeling radial placement error of an object on a table
+ dist = RayleighDistribution(name="placement_error", scale=0.02)
+ ```
+
+ References:
+ 1. [NumPy](https://numpy.org/doc/stable/reference/random/generated/numpy.random.rayleigh.html)
+ 2. [SciPy](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rayleigh.html)
+ 3. [Wikipedia](https://en.wikipedia.org/wiki/Rayleigh_distribution)
+
+ Note:
+  +
+ """
+
+ scale: float
+ """Scale parameter (sigma). Must be positive."""
+
+ _scipy: rv_continuous = PrivateAttr()
+
+ dist_type: Literal[DistType.RAYLEIGH] = DistType.RAYLEIGH
+
+ @model_validator(mode="after")
+ def validate_scale(self) -> Self:
+ if self.scale <= 0:
+ msg = f"Distribution {self.name} has a non-positive scale. It must be greater than 0."
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ @model_validator(mode="after")
+ def validate_scipy(self) -> Self:
+ self._scipy = stats.rayleigh(scale=self.scale) # pyright: ignore[reportAttributeAccessIssue]
+ return self
+
+ def draw(self, size: int = 1) -> np.ndarray:
+ return self.rng.rayleigh(scale=self.scale, size=size)
+
+ @property
+ def is_continuous(self) -> Literal[True]:
+ return True
+
+ def pdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.pdf(x)
+
+ def cdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.cdf(x)
+
+ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.ppf(q)
+
+
class BernoulliDistribution(Distribution[bool]):
"""
Represent a single binary trial (Success/Failure).
@@ -869,7 +999,7 @@ class BernoulliDistribution(Distribution[bool]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Bernoulli_distribution)
Note:
-
+
+ """
+
+ scale: float
+ """Scale parameter (sigma). Must be positive."""
+
+ _scipy: rv_continuous = PrivateAttr()
+
+ dist_type: Literal[DistType.RAYLEIGH] = DistType.RAYLEIGH
+
+ @model_validator(mode="after")
+ def validate_scale(self) -> Self:
+ if self.scale <= 0:
+ msg = f"Distribution {self.name} has a non-positive scale. It must be greater than 0."
+ logger.error(msg)
+ raise ValueError(msg)
+ return self
+
+ @model_validator(mode="after")
+ def validate_scipy(self) -> Self:
+ self._scipy = stats.rayleigh(scale=self.scale) # pyright: ignore[reportAttributeAccessIssue]
+ return self
+
+ def draw(self, size: int = 1) -> np.ndarray:
+ return self.rng.rayleigh(scale=self.scale, size=size)
+
+ @property
+ def is_continuous(self) -> Literal[True]:
+ return True
+
+ def pdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.pdf(x)
+
+ def cdf(self, x: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.cdf(x)
+
+ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
+ return self._scipy.ppf(q)
+
+
class BernoulliDistribution(Distribution[bool]):
"""
Represent a single binary trial (Success/Failure).
@@ -869,7 +999,7 @@ class BernoulliDistribution(Distribution[bool]):
3. [Wikipedia](https://en.wikipedia.org/wiki/Bernoulli_distribution)
Note:
-  +
+  """
@@ -920,11 +1050,13 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
| UniformDistribution
| CategoricalDistribution
| PermutationDistribution
+ | DiscreteUniformDistribution
| TriangularDistribution
| TruncatedNormalDistribution
| LogNormalDistribution
| PoissonDistribution
| ExponentialDistribution
+ | RayleighDistribution
| BernoulliDistribution,
Field(discriminator="dist_type"),
]
diff --git a/src/process_manager/mixins.py b/src/stochas/mixins.py
similarity index 100%
rename from src/process_manager/mixins.py
rename to src/stochas/mixins.py
diff --git a/src/process_manager/named_value.py b/src/stochas/named_value.py
similarity index 69%
rename from src/process_manager/named_value.py
rename to src/stochas/named_value.py
index 03bdf9e..b454257 100644
--- a/src/process_manager/named_value.py
+++ b/src/stochas/named_value.py
@@ -2,12 +2,22 @@
import logging
from enum import StrEnum
-from typing import Any, Literal, NewType, Self
-
-from pydantic import BaseModel, ConfigDict, Field, model_validator
-
-from process_manager.base_collections import BaseDict, BaseList
-from process_manager.mixins import NumericMixin
+from typing import Annotated, Any, Literal, NewType, Self, cast
+
+from pydantic import (
+ BaseModel,
+ BeforeValidator,
+ ConfigDict,
+ Field,
+ FieldSerializationInfo,
+ field_serializer,
+ model_validator,
+)
+from pydantic_core import to_jsonable_python
+
+from stochas.base_collections import BaseDict, BaseList
+from stochas.mixins import NumericMixin
+from stochas.utils import _reconstruct_obj
__all__ = [
"NamedValue",
@@ -24,6 +34,10 @@
"""Alias of string. Used to type hint a named value's name."""
+UNSET_SENTINEL = "__STOCHAS_UNSET_SENTINEL__"
+UnsetType = Literal["__STOCHAS_UNSET_SENTINEL__"]
+
+
class Val(BaseModel):
"""
Defines a reference to a variable name.
@@ -45,6 +59,16 @@ class NamedValueState(StrEnum):
"""The value has been populated and is effectively frozen."""
+def _numpy_safe_sentinel(v: Any) -> Any:
+ """
+ Prevents NumPy from blowing up during Pydantic Union validation.
+ Checks identity/type before allowing a comparison to occur.
+ """
+ if isinstance(v, str) and v == UNSET_SENTINEL:
+ return UNSET_SENTINEL
+ return v
+
+
class NamedValue[T](BaseModel, NumericMixin):
"""
A container for a sampled variable that tracks its initialization state.
@@ -69,20 +93,55 @@ class NamedValue[T](BaseModel, NumericMixin):
state: NamedValueState = Field(default=NamedValueState.UNSET)
"""The current lifecycle state (SET or UNSET)."""
- stored_value: T | Literal[NamedValueState.UNSET] = Field(
- default=NamedValueState.UNSET
+ stored_value: Annotated[T | UnsetType, BeforeValidator(_numpy_safe_sentinel)] = (
+ Field(default=UNSET_SENTINEL)
)
"""The actual data held by this container."""
+ def __reduce__(self):
+ return (
+ _reconstruct_obj,
+ (self.__class__.__module__, self.__class__.__name__, self.model_dump()),
+ )
+
+ def __setstate__(self, state):
+ """Re-injects the data into the Pydantic model after unpickling."""
+ self.__dict__.update(state) # pyright: ignore[reportAttributeAccessIssue]
+
+ @field_serializer("stored_value", mode="plain", when_used="always")
+ def _serialize_value(self, v: Any, info: FieldSerializationInfo) -> Any:
+ """
+ Silences the Pydantic Union warnings by providing a single-path serializer.
+
+ Use to_jsonable_python to ensure numpy arrays (and any other T) are correctly converted to JSON primitives.
+ """
+ if isinstance(v, str) and v == UNSET_SENTINEL:
+ return UNSET_SENTINEL
+
+ # 2. Handle NumPy / Array-like types
+ if hasattr(v, "tolist"):
+ # If model_dump_json() or mode='json', we MUST return a list
+ if info.mode == "json":
+ return v.tolist() # pyright: ignore[reportAttributeAccessIssue]
+ # If model_dump() or mode='python', return the raw array for tests
+ return v
+
+ # 3. Handle everything else (floats, ints, etc.)
+ return to_jsonable_python(v) if info.mode == "json" else v
+
@model_validator(mode="after")
def validate_state(self) -> Self:
"""Synchronizes the state enum with the actual stored_value content."""
+ is_sentinel = (
+ isinstance(self.stored_value, str) and self.stored_value == UNSET_SENTINEL
+ )
+
match self.state:
case NamedValueState.UNSET:
- if self.stored_value is not NamedValueState.UNSET:
+ if not is_sentinel:
self.state = NamedValueState.SET
case NamedValueState.SET:
- if self.stored_value is NamedValueState.UNSET:
+ if is_sentinel:
msg = f"{self.name} stored value cannot be set to `NamedValueState.UNSET`"
logger.error(msg)
raise ValueError(msg)
@@ -102,18 +161,22 @@ def value(self) -> T:
RuntimeError: If the internal state is corrupted.
"""
+ is_sentinel = (
+ isinstance(self.stored_value, str) and self.stored_value == UNSET_SENTINEL
+ )
+
match self.state:
case NamedValueState.UNSET:
msg = f"Value for NamedValue {self.name} has not been set."
logger.error(msg)
raise ValueError(msg)
case NamedValueState.SET:
- if self.stored_value is NamedValueState.UNSET:
+ if is_sentinel:
# Defensive: impossible unless model was corrupted
- msg = f"NamedValue '{self.name}' is set but stored_value is `NamedValueState.SET`"
+ msg = f"NamedValue '{self.name}' is set but stored_value is unset implying something was corrupted!"
logger.error(msg)
raise RuntimeError(msg)
- return self.stored_value
+ return cast(T, self.stored_value)
case _:
msg = f"The enumeration for {self.state} has not been implemented."
logger.error(msg)
diff --git a/src/stochas/utils.py b/src/stochas/utils.py
new file mode 100644
index 0000000..18a4304
--- /dev/null
+++ b/src/stochas/utils.py
@@ -0,0 +1,23 @@
+import importlib
+from typing import Any
+
+
+def _reconstruct_obj(module_name: str, class_name: str, data: Any):
+ """
+ Dynamically imports the correct module and class to re-hydrate objects in a worker process.
+ """
+ # find the module where the class actually lives
+ module = importlib.import_module(module_name)
+
+ # strip generic type parameters if present (e.g., 'NamedValueDict[NDArray]' -> 'NamedValueDict')
+ # This handles generic classes like NamedValueDict[T], NamedValueList[T], etc.
+ if "[" in class_name:
+ base_class_name = class_name.split("[")[0]
+ else:
+ base_class_name = class_name
+
+ # get the unspecialized base class
+ cls = getattr(module, base_class_name)
+
+ # use Pydantic's universal loader
+ return cls.model_validate(data)
diff --git a/tests/data_handlers/distributions/base_test.py b/tests/data_handlers/distributions/base_test.py
index 5362364..a092d22 100644
--- a/tests/data_handlers/distributions/base_test.py
+++ b/tests/data_handlers/distributions/base_test.py
@@ -1,9 +1,9 @@
import numpy as np
from numpydantic import NDArray
-from process_manager import DistName, NormalDistribution
-from process_manager.distribution import DistributionDict
-from process_manager.named_value import NamedValueDict
+from stochas import DistName, NormalDistribution
+from stochas.distribution import DistributionDict
+from stochas.named_value import NamedValueDict
def test_distribution_seeding_and_salting():
diff --git a/tests/data_handlers/distributions/continuous_test.py b/tests/data_handlers/distributions/continuous_test.py
index b7c8ab9..d6c2c26 100644
--- a/tests/data_handlers/distributions/continuous_test.py
+++ b/tests/data_handlers/distributions/continuous_test.py
@@ -1,11 +1,12 @@
import numpy as np
import pytest
-from process_manager import (
+from stochas import (
DistName,
ExponentialDistribution,
LogNormalDistribution,
NormalDistribution,
+ RayleighDistribution,
TriangularDistribution,
TruncatedNormalDistribution,
UniformDistribution,
@@ -100,6 +101,29 @@ def test_exponential_properties():
assert np.isclose(dist.cdf(expected_mean), 1 - np.exp(-1))
+def test_rayleigh_properties():
+ """Verify Rayleigh distribution follows the scale (sigma) parameter."""
+ scale = 2.0
+ dist = RayleighDistribution(name=DistName("error"), scale=scale)
+
+ samples = dist.sample(1000)
+ assert np.all(samples >= 0)
+
+ # Theoretical mean of Rayleigh is scale * sqrt(pi / 2)
+ expected_mean = scale * np.sqrt(np.pi / 2)
+ assert np.isclose(np.mean(samples), expected_mean, atol=0.2)
+
+ # Median of Rayleigh is scale * sqrt(ln(4))
+ median = scale * np.sqrt(np.log(4))
+ assert np.isclose(dist.cdf(median), 0.5)
+ assert np.isclose(dist.ppf(0.5), median)
+
+
+def test_rayleigh_validation():
+ with pytest.raises(ValueError, match="non-positive scale"):
+ RayleighDistribution(name=DistName("bad"), scale=0)
+
+
@pytest.mark.parametrize(
"dist_instance",
[
@@ -108,6 +132,7 @@ def test_exponential_properties():
),
LogNormalDistribution(name=DistName("ln"), s=0.5, scale=10),
ExponentialDistribution(name=DistName("ex"), lam=2.0),
+ RayleighDistribution(name=DistName("ry"), scale=2.0),
],
)
def test_continuous_ppf_consistency(dist_instance):
diff --git a/tests/data_handlers/distributions/discrete_test.py b/tests/data_handlers/distributions/discrete_test.py
index 5b252fc..b76e2a4 100644
--- a/tests/data_handlers/distributions/discrete_test.py
+++ b/tests/data_handlers/distributions/discrete_test.py
@@ -1,14 +1,14 @@
import numpy as np
import pytest
-from process_manager import (
+from stochas import (
BernoulliDistribution,
CategoricalDistribution,
DistName,
PoissonDistribution,
)
-from process_manager.distribution import DistributionDict, PermutationDistribution
-from process_manager.named_value import NamedValueDict
+from stochas.distribution import DistributionDict, PermutationDistribution
+from stochas.named_value import NamedValueDict
def test_categorical_pmf_cdf():
diff --git a/tests/data_handlers/named_value_collection_test.py b/tests/data_handlers/named_value_collection_test.py
index 0819f4d..0cc2d88 100644
--- a/tests/data_handlers/named_value_collection_test.py
+++ b/tests/data_handlers/named_value_collection_test.py
@@ -1,7 +1,7 @@
import pytest
-from process_manager import NamedValue, NamedValueDict, NamedValueList
-from process_manager.named_value import ValueName
+from stochas import NamedValue, NamedValueDict, NamedValueList
+from stochas.named_value import ValueName
def test_dict_setitem_validation():
diff --git a/tests/data_handlers/named_value_test.py b/tests/data_handlers/named_value_test.py
index de687b6..6abf816 100644
--- a/tests/data_handlers/named_value_test.py
+++ b/tests/data_handlers/named_value_test.py
@@ -1,8 +1,8 @@
import pytest
from pydantic import ValidationError
-from process_manager import NamedValue, NamedValueState
-from process_manager.named_value import ValueName
+from stochas import NamedValue, NamedValueState
+from stochas.named_value import ValueName
def test_initial_state_unset():
diff --git a/uv.lock b/uv.lock
index 2cce38a..9d6fb00 100644
--- a/uv.lock
+++ b/uv.lock
@@ -638,7 +638,7 @@ wheels = [
]
[[package]]
-name = "process-manager"
+name = "stochas"
version = "0.1.0"
source = { editable = "." }
dependencies = [
"""
@@ -920,11 +1050,13 @@ def ppf(self, q: float | np.ndarray) -> float | np.ndarray:
| UniformDistribution
| CategoricalDistribution
| PermutationDistribution
+ | DiscreteUniformDistribution
| TriangularDistribution
| TruncatedNormalDistribution
| LogNormalDistribution
| PoissonDistribution
| ExponentialDistribution
+ | RayleighDistribution
| BernoulliDistribution,
Field(discriminator="dist_type"),
]
diff --git a/src/process_manager/mixins.py b/src/stochas/mixins.py
similarity index 100%
rename from src/process_manager/mixins.py
rename to src/stochas/mixins.py
diff --git a/src/process_manager/named_value.py b/src/stochas/named_value.py
similarity index 69%
rename from src/process_manager/named_value.py
rename to src/stochas/named_value.py
index 03bdf9e..b454257 100644
--- a/src/process_manager/named_value.py
+++ b/src/stochas/named_value.py
@@ -2,12 +2,22 @@
import logging
from enum import StrEnum
-from typing import Any, Literal, NewType, Self
-
-from pydantic import BaseModel, ConfigDict, Field, model_validator
-
-from process_manager.base_collections import BaseDict, BaseList
-from process_manager.mixins import NumericMixin
+from typing import Annotated, Any, Literal, NewType, Self, cast
+
+from pydantic import (
+ BaseModel,
+ BeforeValidator,
+ ConfigDict,
+ Field,
+ FieldSerializationInfo,
+ field_serializer,
+ model_validator,
+)
+from pydantic_core import to_jsonable_python
+
+from stochas.base_collections import BaseDict, BaseList
+from stochas.mixins import NumericMixin
+from stochas.utils import _reconstruct_obj
__all__ = [
"NamedValue",
@@ -24,6 +34,10 @@
"""Alias of string. Used to type hint a named value's name."""
+UNSET_SENTINEL = "__STOCHAS_UNSET_SENTINEL__"
+UnsetType = Literal["__STOCHAS_UNSET_SENTINEL__"]
+
+
class Val(BaseModel):
"""
Defines a reference to a variable name.
@@ -45,6 +59,16 @@ class NamedValueState(StrEnum):
"""The value has been populated and is effectively frozen."""
+def _numpy_safe_sentinel(v: Any) -> Any:
+ """
+ Prevents NumPy from blowing up during Pydantic Union validation.
+ Checks identity/type before allowing a comparison to occur.
+ """
+ if isinstance(v, str) and v == UNSET_SENTINEL:
+ return UNSET_SENTINEL
+ return v
+
+
class NamedValue[T](BaseModel, NumericMixin):
"""
A container for a sampled variable that tracks its initialization state.
@@ -69,20 +93,55 @@ class NamedValue[T](BaseModel, NumericMixin):
state: NamedValueState = Field(default=NamedValueState.UNSET)
"""The current lifecycle state (SET or UNSET)."""
- stored_value: T | Literal[NamedValueState.UNSET] = Field(
- default=NamedValueState.UNSET
+ stored_value: Annotated[T | UnsetType, BeforeValidator(_numpy_safe_sentinel)] = (
+ Field(default=UNSET_SENTINEL)
)
"""The actual data held by this container."""
+ def __reduce__(self):
+ return (
+ _reconstruct_obj,
+ (self.__class__.__module__, self.__class__.__name__, self.model_dump()),
+ )
+
+ def __setstate__(self, state):
+ """Re-injects the data into the Pydantic model after unpickling."""
+ self.__dict__.update(state) # pyright: ignore[reportAttributeAccessIssue]
+
+ @field_serializer("stored_value", mode="plain", when_used="always")
+ def _serialize_value(self, v: Any, info: FieldSerializationInfo) -> Any:
+ """
+ Silences the Pydantic Union warnings by providing a single-path serializer.
+
+ Use to_jsonable_python to ensure numpy arrays (and any other T) are correctly converted to JSON primitives.
+ """
+ if isinstance(v, str) and v == UNSET_SENTINEL:
+ return UNSET_SENTINEL
+
+ # 2. Handle NumPy / Array-like types
+ if hasattr(v, "tolist"):
+ # If model_dump_json() or mode='json', we MUST return a list
+ if info.mode == "json":
+ return v.tolist() # pyright: ignore[reportAttributeAccessIssue]
+ # If model_dump() or mode='python', return the raw array for tests
+ return v
+
+ # 3. Handle everything else (floats, ints, etc.)
+ return to_jsonable_python(v) if info.mode == "json" else v
+
@model_validator(mode="after")
def validate_state(self) -> Self:
"""Synchronizes the state enum with the actual stored_value content."""
+ is_sentinel = (
+ isinstance(self.stored_value, str) and self.stored_value == UNSET_SENTINEL
+ )
+
match self.state:
case NamedValueState.UNSET:
- if self.stored_value is not NamedValueState.UNSET:
+ if not is_sentinel:
self.state = NamedValueState.SET
case NamedValueState.SET:
- if self.stored_value is NamedValueState.UNSET:
+ if is_sentinel:
msg = f"{self.name} stored value cannot be set to `NamedValueState.UNSET`"
logger.error(msg)
raise ValueError(msg)
@@ -102,18 +161,22 @@ def value(self) -> T:
RuntimeError: If the internal state is corrupted.
"""
+ is_sentinel = (
+ isinstance(self.stored_value, str) and self.stored_value == UNSET_SENTINEL
+ )
+
match self.state:
case NamedValueState.UNSET:
msg = f"Value for NamedValue {self.name} has not been set."
logger.error(msg)
raise ValueError(msg)
case NamedValueState.SET:
- if self.stored_value is NamedValueState.UNSET:
+ if is_sentinel:
# Defensive: impossible unless model was corrupted
- msg = f"NamedValue '{self.name}' is set but stored_value is `NamedValueState.SET`"
+ msg = f"NamedValue '{self.name}' is set but stored_value is unset implying something was corrupted!"
logger.error(msg)
raise RuntimeError(msg)
- return self.stored_value
+ return cast(T, self.stored_value)
case _:
msg = f"The enumeration for {self.state} has not been implemented."
logger.error(msg)
diff --git a/src/stochas/utils.py b/src/stochas/utils.py
new file mode 100644
index 0000000..18a4304
--- /dev/null
+++ b/src/stochas/utils.py
@@ -0,0 +1,23 @@
+import importlib
+from typing import Any
+
+
+def _reconstruct_obj(module_name: str, class_name: str, data: Any):
+ """
+ Dynamically imports the correct module and class to re-hydrate objects in a worker process.
+ """
+ # find the module where the class actually lives
+ module = importlib.import_module(module_name)
+
+ # strip generic type parameters if present (e.g., 'NamedValueDict[NDArray]' -> 'NamedValueDict')
+ # This handles generic classes like NamedValueDict[T], NamedValueList[T], etc.
+ if "[" in class_name:
+ base_class_name = class_name.split("[")[0]
+ else:
+ base_class_name = class_name
+
+ # get the unspecialized base class
+ cls = getattr(module, base_class_name)
+
+ # use Pydantic's universal loader
+ return cls.model_validate(data)
diff --git a/tests/data_handlers/distributions/base_test.py b/tests/data_handlers/distributions/base_test.py
index 5362364..a092d22 100644
--- a/tests/data_handlers/distributions/base_test.py
+++ b/tests/data_handlers/distributions/base_test.py
@@ -1,9 +1,9 @@
import numpy as np
from numpydantic import NDArray
-from process_manager import DistName, NormalDistribution
-from process_manager.distribution import DistributionDict
-from process_manager.named_value import NamedValueDict
+from stochas import DistName, NormalDistribution
+from stochas.distribution import DistributionDict
+from stochas.named_value import NamedValueDict
def test_distribution_seeding_and_salting():
diff --git a/tests/data_handlers/distributions/continuous_test.py b/tests/data_handlers/distributions/continuous_test.py
index b7c8ab9..d6c2c26 100644
--- a/tests/data_handlers/distributions/continuous_test.py
+++ b/tests/data_handlers/distributions/continuous_test.py
@@ -1,11 +1,12 @@
import numpy as np
import pytest
-from process_manager import (
+from stochas import (
DistName,
ExponentialDistribution,
LogNormalDistribution,
NormalDistribution,
+ RayleighDistribution,
TriangularDistribution,
TruncatedNormalDistribution,
UniformDistribution,
@@ -100,6 +101,29 @@ def test_exponential_properties():
assert np.isclose(dist.cdf(expected_mean), 1 - np.exp(-1))
+def test_rayleigh_properties():
+ """Verify Rayleigh distribution follows the scale (sigma) parameter."""
+ scale = 2.0
+ dist = RayleighDistribution(name=DistName("error"), scale=scale)
+
+ samples = dist.sample(1000)
+ assert np.all(samples >= 0)
+
+ # Theoretical mean of Rayleigh is scale * sqrt(pi / 2)
+ expected_mean = scale * np.sqrt(np.pi / 2)
+ assert np.isclose(np.mean(samples), expected_mean, atol=0.2)
+
+ # Median of Rayleigh is scale * sqrt(ln(4))
+ median = scale * np.sqrt(np.log(4))
+ assert np.isclose(dist.cdf(median), 0.5)
+ assert np.isclose(dist.ppf(0.5), median)
+
+
+def test_rayleigh_validation():
+ with pytest.raises(ValueError, match="non-positive scale"):
+ RayleighDistribution(name=DistName("bad"), scale=0)
+
+
@pytest.mark.parametrize(
"dist_instance",
[
@@ -108,6 +132,7 @@ def test_exponential_properties():
),
LogNormalDistribution(name=DistName("ln"), s=0.5, scale=10),
ExponentialDistribution(name=DistName("ex"), lam=2.0),
+ RayleighDistribution(name=DistName("ry"), scale=2.0),
],
)
def test_continuous_ppf_consistency(dist_instance):
diff --git a/tests/data_handlers/distributions/discrete_test.py b/tests/data_handlers/distributions/discrete_test.py
index 5b252fc..b76e2a4 100644
--- a/tests/data_handlers/distributions/discrete_test.py
+++ b/tests/data_handlers/distributions/discrete_test.py
@@ -1,14 +1,14 @@
import numpy as np
import pytest
-from process_manager import (
+from stochas import (
BernoulliDistribution,
CategoricalDistribution,
DistName,
PoissonDistribution,
)
-from process_manager.distribution import DistributionDict, PermutationDistribution
-from process_manager.named_value import NamedValueDict
+from stochas.distribution import DistributionDict, PermutationDistribution
+from stochas.named_value import NamedValueDict
def test_categorical_pmf_cdf():
diff --git a/tests/data_handlers/named_value_collection_test.py b/tests/data_handlers/named_value_collection_test.py
index 0819f4d..0cc2d88 100644
--- a/tests/data_handlers/named_value_collection_test.py
+++ b/tests/data_handlers/named_value_collection_test.py
@@ -1,7 +1,7 @@
import pytest
-from process_manager import NamedValue, NamedValueDict, NamedValueList
-from process_manager.named_value import ValueName
+from stochas import NamedValue, NamedValueDict, NamedValueList
+from stochas.named_value import ValueName
def test_dict_setitem_validation():
diff --git a/tests/data_handlers/named_value_test.py b/tests/data_handlers/named_value_test.py
index de687b6..6abf816 100644
--- a/tests/data_handlers/named_value_test.py
+++ b/tests/data_handlers/named_value_test.py
@@ -1,8 +1,8 @@
import pytest
from pydantic import ValidationError
-from process_manager import NamedValue, NamedValueState
-from process_manager.named_value import ValueName
+from stochas import NamedValue, NamedValueState
+from stochas.named_value import ValueName
def test_initial_state_unset():
diff --git a/uv.lock b/uv.lock
index 2cce38a..9d6fb00 100644
--- a/uv.lock
+++ b/uv.lock
@@ -638,7 +638,7 @@ wheels = [
]
[[package]]
-name = "process-manager"
+name = "stochas"
version = "0.1.0"
source = { editable = "." }
dependencies = [