|
12 | 12 | content: 对比 JDK7/8 的 ConcurrentHashMap 实现,解析分段锁、CAS、链表/红黑树等并发设计,理解线程安全 Map 的核心原理。 |
13 | 13 | --- |
14 | 14 |
|
15 | | -> 本文来自公众号:末读代码的投稿,原文地址:<https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw> 。 |
| 15 | +> 本文来自末读代码投稿:<https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw> ,JavaGuide 对原文进行了大篇幅改进优化。 |
16 | 16 |
|
17 | 17 | 上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢? |
18 | 18 |
|
@@ -420,6 +420,8 @@ public V get(Object key) { |
420 | 420 |
|
421 | 421 | ## 2. ConcurrentHashMap 1.8 |
422 | 422 |
|
| 423 | +总的来说 ,`ConcurrentHashMap` 在 Java8 中相对于 Java7 来说变化还是挺大的, |
| 424 | + |
423 | 425 | ### 1. 存储结构 |
424 | 426 |
|
425 | 427 | 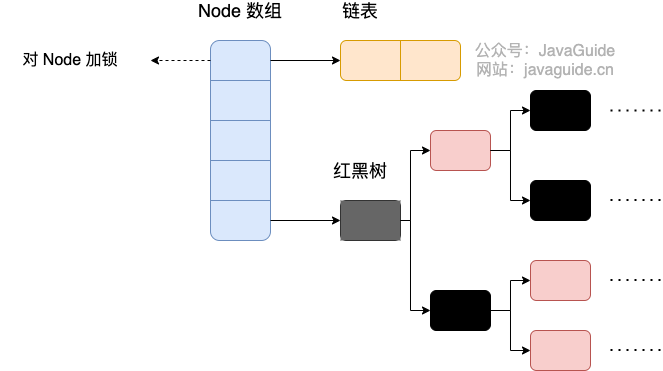 |
@@ -612,41 +614,49 @@ public V get(Object key) { |
612 | 614 | `ConcurrentHashMap` 内部维护了两个关键的计数相关字段: |
613 | 615 |
|
614 | 616 | - **baseCount**:基础计数器,在没有竞争的情况下,直接通过 CAS 更新这个变量。可以把它理解为"主计数器"。 |
615 | | -- **counterCells**:计数器数组,当多个线程竞争 `baseCount` 失败时,会尝试将计数增量分散到 `counterCells` 数组的不同位置。每个线程根据其线程 ID 映射到数组的某个位置,在自己的"专属格子"里进行计数累加,从而避免竞争。 |
| 617 | +- **counterCells**:计数器数组。当多个线程竞争 `baseCount` 失败时,会尝试将计数增量分散到 `counterCells` 数组的不同位置。 |
| 618 | + - 每个线程根据自己的 **Probe 值**(可理解为线程 ID 生成的一种哈希码)映射到数组的某个槽位,优先在这个“偏向的格子”里进行累加。 |
| 619 | + - **注意**:这个格子并不是严格意义上的“线程私有”,当哈希冲突时,多个线程仍然可能映射到同一个槽位并发更新。 |
616 | 620 |
|
617 | | -**举个例子**:假设有 10 个线程同时往 Map 中添加元素。第一个线程成功通过 CAS 更新了 `baseCount`,但后面 9 个线程在更新 `baseCount` 时发现有竞争,就会转而去 `counterCells` 数组中找一个位置进行累加。这 9 个线程可能分散到数组的不同位置,比如线程 2 在 `counterCells[1]` 累加,线程 3 在 `counterCells[2]` 累加,以此类推。这样就把竞争从一个点分散到了多个点,大大降低了冲突概率。 |
| 621 | +**举个例子**:假设有 10 个线程同时往 Map 中添加元素。第一个线程成功通过 CAS 更新了 `baseCount`,但后面 9 个线程在更新 `baseCount` 时发现有竞争,就会转而去 `counterCells` 数组中找一个位置进行累加。这 9 个线程可能分散到数组的不同位置(比如线程 2 在 `counterCells[1]`,线程 3 在 `counterCells[2]`),从而将竞争从一个点分散到了多个点。。 |
618 | 622 |
|
619 | 623 | #### 5.3 put 元素时如何更新计数 |
620 | 624 |
|
621 | 625 | 在 `putVal` 方法的最后,我们可以看到调用了 `addCount(1L, binCount)` 方法,这个方法就是用来更新元素计数的。 |
622 | 626 |
|
623 | | -`addCount` 的执行逻辑如下: |
624 | | - |
625 | | -1. **优先尝试更新 baseCount**:首先尝试通过 CAS 操作直接更新 `baseCount`,如果成功就结束。这是最理想的情况,没有竞争,性能最高。 |
| 627 | +`addCount` 的执行逻辑大致可以概括为: |
626 | 628 |
|
627 | | -2. **竞争时使用 counterCells**:如果 CAS 更新 `baseCount` 失败(说明有其他线程在竞争),则会尝试在 `counterCells` 数组中找到一个属于当前线程的位置,然后对该位置的计数值进行 CAS 累加。 |
| 629 | +1. **优先尝试更新 baseCount** |
628 | 630 |
|
629 | | -3. **动态扩容 counterCells**:如果 `counterCells` 数组还未初始化,或者数组中的某个位置依然存在激烈竞争,`addCount` 方法会动态地扩容 `counterCells` 数组,增加更多的计数槽位,进一步分散竞争。 |
| 631 | + - 如果当前还没有启用 `counterCells`(`counterCells == null`),线程会先尝试通过 CAS 直接更新 `baseCount`。 |
| 632 | + - 如果 CAS 成功,说明竞争不激烈,直接返回即可。 |
630 | 633 |
|
631 | | -这种设计保证了在低并发时使用简单的 `baseCount`,在高并发时自动切换到分段计数,兼顾了性能和准确性。 |
| 634 | +2. **竞争出现时,转向 counterCells** |
632 | 635 |
|
633 | | -#### 5.4 sumCount 如何计算元素总数 |
| 636 | + - 如果 CAS 更新 `baseCount` 失败(说明有其他线程在竞争),或者 `counterCells` 已经存在(说明系统之前已经遇到过竞争),线程就会尝试在 `counterCells` 中更新: |
| 637 | + - 根据自己的 probe 值映射到某个槽位; |
| 638 | + - 对该槽位对应的 `CounterCell` 做一次 CAS 累加。 |
| 639 | + - 如果这个槽位为空或 CAS 仍然冲突,就会进入一个更“重”的路径 `fullAddCount`,在里面负责初始化槽位、重新选择槽位等。 |
634 | 640 |
|
635 | | -当我们调用 `size()` 方法时,最终会调用 `sumCount()` 方法来计算元素总数。`sumCount()` 的逻辑非常简单直接: |
| 641 | +3. **动态初始化与扩容 counterCells** |
| 642 | + - 当检测到竞争比较激烈(例如:某个 cell 的 CAS 也频繁失败)时,`fullAddCount` 会在一个轻量级的自旋锁 `cellsBusy` 保护下: |
| 643 | + - 如果 `counterCells` 还没初始化,就初始化一个较小的数组(比如长度 2); |
| 644 | + - 如果已经存在并且长度还没达到上限(通常不超过 CPU 核数),就按 2 倍进行扩容,增加更多的计数槽位,把线程进一步打散。 |
636 | 645 |
|
637 | | -1. 先读取 `baseCount` 的值作为基础值 |
638 | | -2. 遍历整个 `counterCells` 数组,将每个位置的计数值累加到基础值上 |
639 | | -3. 返回最终的累加结果 |
| 646 | +这种设计保证了:在低并发时只使用简单的 `baseCount`,路径非常短;在高并发时则自动切换到分段计数,通过 `counterCells` 和扩容机制摊薄竞争,兼顾了性能和准确性。 |
640 | 647 |
|
641 | | -需要注意的是,`sumCount()` 并不会加锁,所以返回的结果是一个**近似值**。在调用 `size()` 的瞬间,可能有其他线程正在修改计数,因此得到的不一定是完全精确的实时值。但这在实际应用中通常是可以接受的,因为在高并发场景下,"此时此刻的准确元素个数"本身就是一个动态变化的概念。 |
| 648 | +#### 5.4 sumCount 如何计算元素总数 |
642 | 649 |
|
643 | | -**举个例子**:假设当前 `baseCount = 100`,`counterCells` 数组有 4 个元素,分别是 `[5, 8, 3, 6]`,那么 `sumCount()` 返回的结果就是 `100 + 5 + 8 + 3 + 6 = 122`。这个计算过程中不需要加锁,速度很快,即使在计算过程中有新元素插入,影响也很小。 |
| 650 | +当我们调用 `size()` 方法时,最终会调用 `sumCount()` 方法来计算元素总数。`sumCount()` 的逻辑非常简单直接: |
644 | 651 |
|
645 | | -通过这种"无锁读取 + 分段累加"的方式,`size()` 方法在保证性能的同时,也能给出一个合理的元素总数估计值。 |
| 652 | +1. 读取 `baseCount` 的值作为基础值。 |
| 653 | +2. 遍历 `counterCells` 数组,将所有非空位置的计数值累加到基础值上。 |
| 654 | +3. 返回累加结果。 |
646 | 655 |
|
647 | | -总结: |
| 656 | +**注意**: |
648 | 657 |
|
649 | | -总的来说 `ConcurrentHashMap` 在 Java8 中相对于 Java7 来说变化还是挺大的, |
| 658 | +- **弱一致性**:`sumCount()` 全程**不加锁**。在计算期间如果有其他线程插入数据,返回的结果只是一个**近似值**。但在高并发场景下,追求“刹那间的精确总数”代价过大且无意义,近似值通常已足够。 |
| 659 | +- **整型溢出**:`size()` 方法返回 `int` 类型。如果元素数量超过 `Integer.MAX_VALUE`,它只会返回 `Integer.MAX_VALUE`。如果需要获取精确的大容量计数,建议使用 Java 8 新增的 **`mappingCount()`** 方法,该方法返回 `long` 类型。 |
650 | 660 |
|
651 | 661 | ## 3. 总结 |
652 | 662 |
|
|
0 commit comments