| title | 虚拟内存详解:地址转换、TLB、缺页中断与页面置换 | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 虚拟内存高频面试题总结,从进程隔离讲起,讲清虚拟地址到物理地址的分段、分页、多级页表、TLB、缺页中断、页面置换算法、Belady 异常,以及 mmap、COW、JVM 大页等工程场景。 | |||||||
| category | 计算机基础 | |||||||
| tag |
|
|||||||
| head |
|
打开任务管理器时,你可能会看到一个很反直觉的现象:每个进程都像在用一大片“自己的内存”,有的进程地址还长得差不多,但它们并不会互相踩坏。浏览器、IDE、数据库同时跑,大家都以为自己拿到的是连续、干净、独占的一块空间。
为什么能这样呢?难道是因为程序之间互相信任?
这其实是操作系统在中间加了一层翻译。程序看到的是虚拟地址,真正落到内存条上的位置由内核和硬件一起决定。
虚拟内存要解决的,就是这层翻译怎么做、为什么能隔离进程、内存不够时又怎么把一部分数据暂时挪到磁盘上。
先看一个最直白的反例。
很多人大学里玩过单片机。单片机上没有操作系统,CPU 直接操作内存的物理地址。这种环境下想同时跑两个程序,几乎是个灾难:第一个程序往地址 2000 写了个值,第二个程序刚好也把数据放在 2000,那一写就把对方的数据覆盖了,两个程序双双崩溃。
问题的根子在于:两个程序都直接引用了同一套物理地址,谁也躲不开谁。
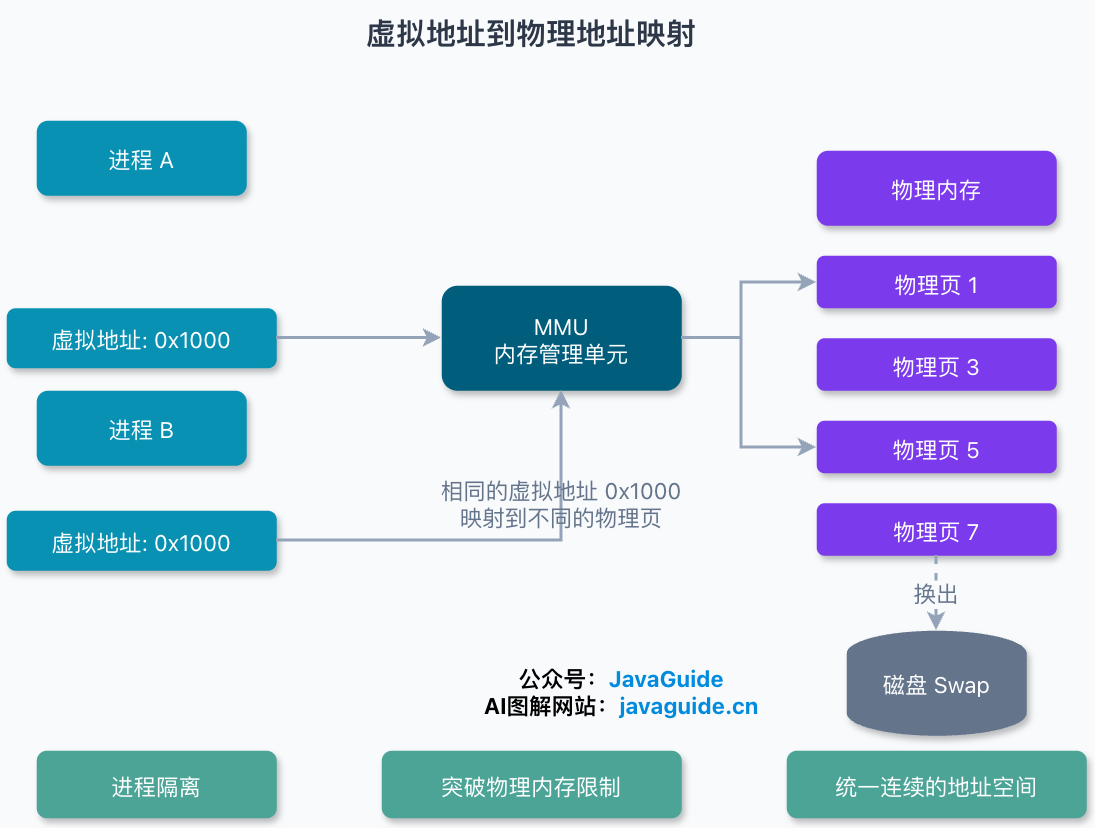
操作系统的办法是加一层隔离:给每个进程发一套独立的“虚拟地址”,让进程只跟自己的虚拟地址打交道,至于这套虚拟地址最后落到物理内存的哪一块,进程根本不需要知道,由操作系统统一安排。
于是有了两个概念:
- 程序里用的地址,叫虚拟地址(Virtual Address)。
- 真正存在内存条上的地址,叫物理地址(Physical Address)。
进程访问虚拟地址时,CPU 里的内存管理单元(MMU)按照映射关系把它翻译成物理地址,再去访问内存。不同进程写的虚拟地址哪怕数值一样,映射到的物理地址也不同,自然就不会打架。
Guide 习惯把虚拟内存的好处归成三条,后面整篇文章其实都在为这三条服务:
- 进程隔离:每个进程一套页表,互相看不到对方的物理内存,A 进程没法通过地址访问 B 进程的数据。
- 突破物理内存大小限制:程序运行有局部性,用不到的页可以先扔到磁盘上,需要时再换回来,于是进程“感觉到”的内存可以比物理内存大。
- 统一且连续的地址空间:进程看到的是一整片连续的虚拟地址,物理上却可以是东一块西一块的碎片,拼接的活儿交给映射表。
接下来的核心问题只有一个:虚拟地址到物理地址,这个映射到底怎么做。历史上有两条路线,分段和分页。
分段(Segmentation)出现得早,思路贴近程序员的直觉。一个程序天然由几类东西组成:代码、数据、栈、堆。它们的访问权限和生命周期都不一样,那就按逻辑切成若干个段。
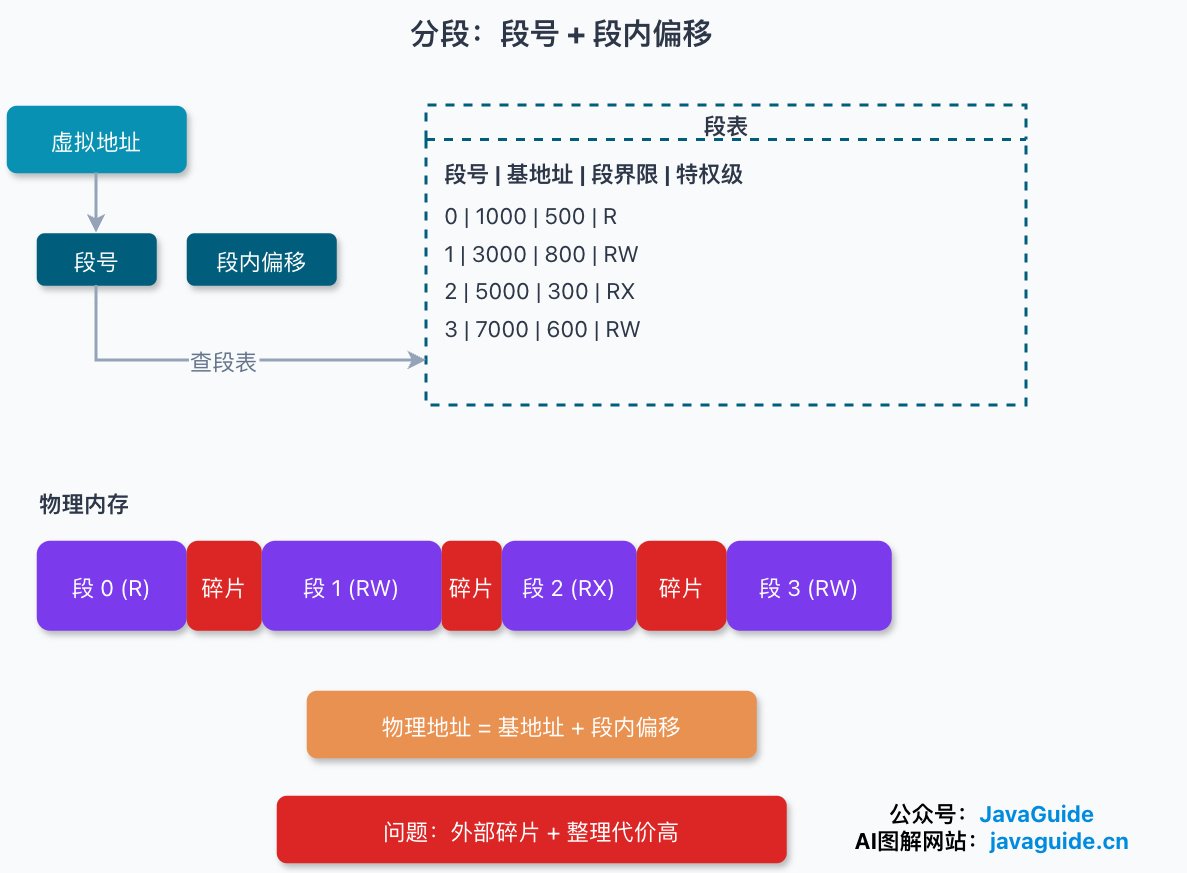
分段下的虚拟地址由两部分构成:段选择子和段内偏移量。段选择子存在段寄存器里,其中最关键的是段号,用来当段表的索引。段表里每一项记着这个段的基地址、段界限(段有多长)和特权级。
翻译过程不复杂:拿段号去段表里查到段基地址,再检查段内偏移量有没有超出段界限,合法的话用基地址加偏移量就得到物理地址。举个例子,要访问段 3 偏移 500 的地址,段 3 基地址是 7000,那物理地址就是 7000 + 500 = 7500。
分段解决了“程序不用关心物理地址”的问题,但留下两个坑。
第一个是外部内存碎片。因为每个段的长度不固定,段与段之间很容易抠出一些零碎的空隙。举个例子,物理内存里依次塞进四段:A 占 256 MB、B 占 128 MB、C 占 256 MB、D 占 128 MB。现在释放掉 B 和 D,空闲总量有 256 MB,但这 256 MB 是被 C 隔开的两块 128 MB,最大的连续空闲块还是只有 128 MB。这时想再开一个需要连续 200 MB 的段,就装不下了——总量够,但没有一块连续的 200 MB。
第二个是整理碎片的代价高。要把零散的空闲拼成连续的一块,得做内存紧凑:把还在用的段挪个位置,重排成连续空间。如果搬移过程还伴随把段换出到磁盘 Swap、再换回来,就会额外引入大块磁盘 I/O。不管哪种方式,变长段这种大粒度的搬移都很重,一旦动到大块头,整机都会卡。
说到底,段的粒度太大、又不固定,碎片和整理这两件事都很难收得住。
分页(Paging)换了个思路:不按逻辑切,而是把虚拟地址空间和物理地址空间都切成固定大小的小块,每一块叫一页(Page)。Linux 下一页默认是 4 KB。
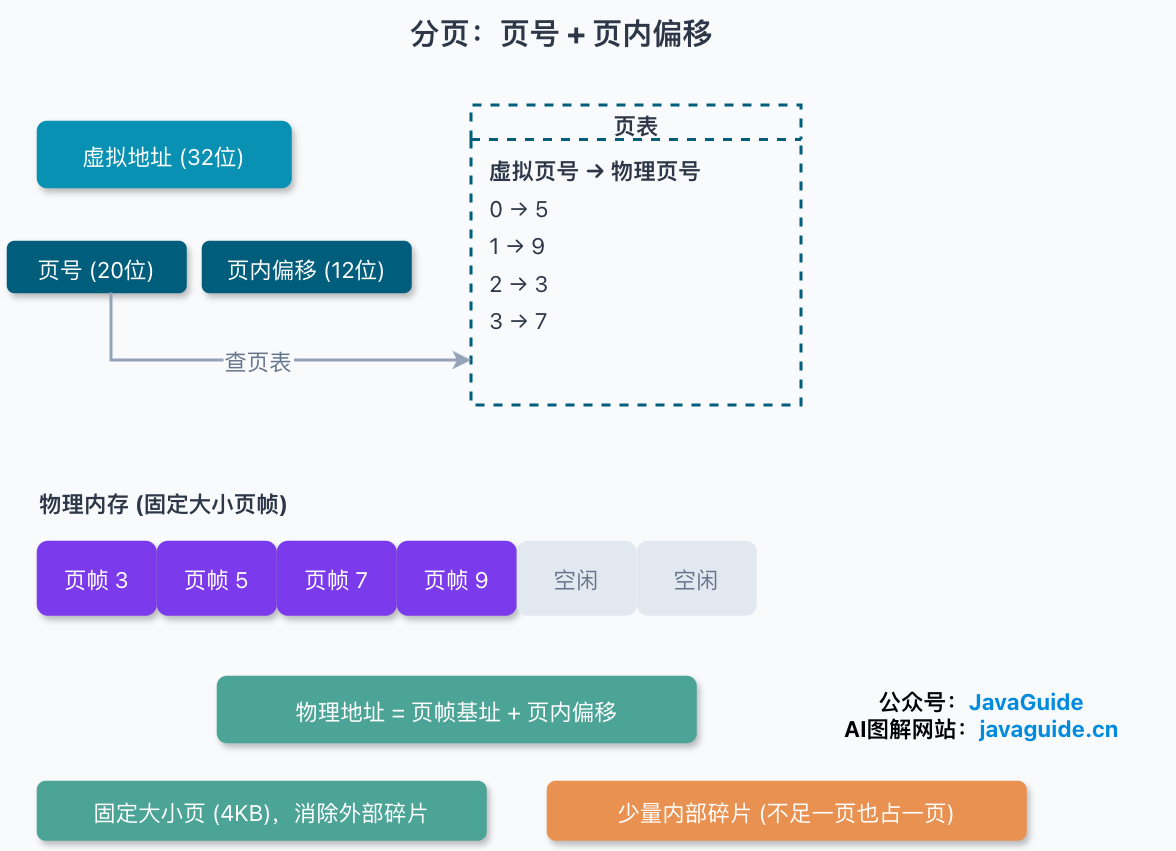
虚拟地址到物理地址通过页表(Page Table)映射,页表存在内存里,由 MMU 负责查表翻译。地址转换分三步:
- 把虚拟地址拆成页号和页内偏移;
- 用页号去页表里查出对应的物理页号;
- 物理页号拼上页内偏移,得到最终物理地址。
分页是怎么缓解分段那两个毛病的?
页是固定大小、紧密排列的,物理页之间没有按段长留下的零碎空隙,所以基本消除了外部碎片。代价是页内可能有浪费:一个程序哪怕只用了几个字节,也得占满一整页,这部分是内部碎片。两害相权,固定页带来的内部碎片可控,比外部碎片好处理得多。
管理粒度也变小了。物理内存不够时,操作系统挑那些“最近没被用到”的页换出到磁盘(Swap Out),需要时再换入(Swap In),调入调出的最小单位从一整个变长段缩到了固定大小的页。不过别误以为分页就一定磁盘压力小:真遇到大量主缺页或抖动,频繁的页级 I/O 照样能把系统拖垮。
更妙的是,分页让程序不必一次性全部装进内存。先把虚拟页和物理页的映射关系建好,但并不真的把页搬进物理内存,等程序真正访问到某个虚拟页时,再把它加载进来。这就是按需调页(Demand Paging)的基础。
分段和分页不是对立的,可以叠在一起用,叫段页式内存管理。
做法是先分段再分页:先把程序切成有逻辑意义的段,再把每个段切成固定大小的页。地址结构因此变成三段:段号、段内页号、页内偏移。每个程序一张段表,每个段再挂一张页表,段表项里存的是该段页表的起始地址。
代价是访问内存的次数变多。一次段页式地址转换要走三趟内存:第一趟查段表拿到页表起始地址,第二趟查页表拿到物理页号,第三趟才用物理页号加页内偏移凑出物理地址。
这里插一段历史,能解释为什么 Linux 看起来“既分段又分页”。Intel 从 80286 开始用段式管理,到 80386 补上了页式管理,但页式是建立在段式之上的:逻辑地址先经段式映射成线性地址(也就是虚拟地址),线性地址再经页式映射成物理地址。CPU 硬件就是这么设计的,Linux 只能照办。
Linux 的对策是让分段形同虚设:把所有段的基地址都设成 0,每个段都覆盖整个 4 GB(32 位下)虚拟空间。这样一来,逻辑地址和线性地址数值上相等,段的概念被架空,只保留访问控制和内存保护的作用。所以严格说,Linux 主要靠分页管理内存。
把分页落到真实系统,简单的单级页表会先在空间上崩掉。
算一笔账。32 位环境下虚拟地址空间是 4 GB,页大小 4 KB(2^12),那一个进程就需要约 100 万(2^20)个页。每个页表项占 4 字节,整张页表就要 4 × 2^20 = 4 MB。
4 MB 看着不大。但要命的是每个进程都有自己的页表。100 个进程就是 400 MB 内存全花在存页表上,64 位环境只会更夸张。
更别扭的是,单级页表必须把整个虚拟地址空间一次性铺满。原因在于页表的职责是翻译地址,万一某个虚拟地址在页表里找不到对应项,翻译就断了。所以哪怕进程实际只用了一小片地址,那 100 万个页表项也得老老实实全部建出来,绝大多数还都是空的。
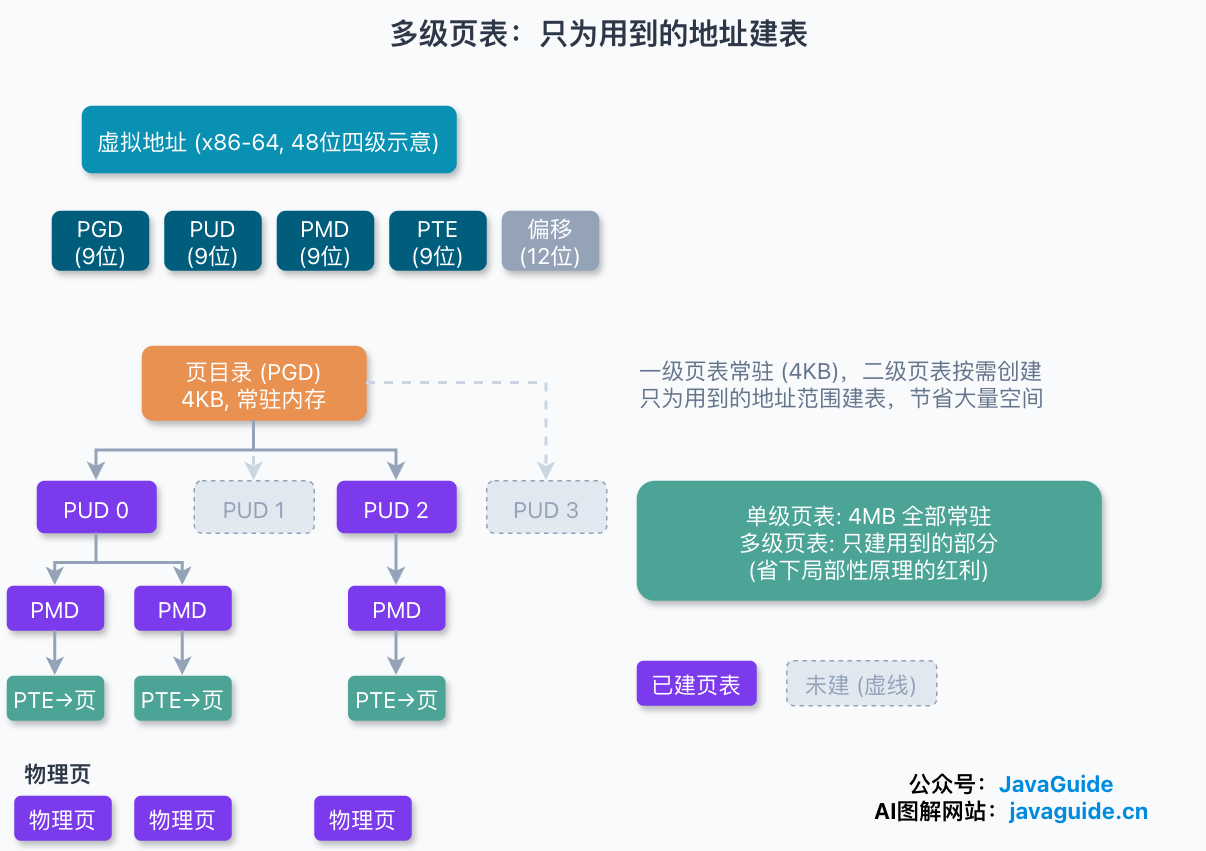
多级页表(Multi-Level Page Table)的核心招数是:只为真正用到的地址建二级表,没用到的不建。
还是 32 位、4 KB 页的场景。把那 100 多万个页表项的单级页表再分一层:一级页表(页目录)有 1024 项,每一项指向一张二级页表,每张二级页表又有 1024 项。1024 × 1024 刚好覆盖 100 多万个页表项。
你可能立刻反驳:这不是多了一层吗,4 KB 的一级表加 4 MB 的二级表,岂不是更费?
如果真把 4 GB 虚拟地址全映射满,确实更费。但现实里没有进程会用满 4 GB。关键就在这:一级页表必须常驻,它要覆盖全部地址空间,但它只占 4 KB;而二级页表是按需创建的,某个一级表项没被用到,对应的那张二级表就根本不建。
算个数。假设只有 20% 的一级表项被用到,那页表总开销就是 4 KB(一级)+ 20% × 4 MB(二级)≈ 0.804 MB,对比单级的 4 MB,省了一大截。省下的这部分,吃的是局部性原理的红利:程序在一段时间内只访问地址空间里的一小块。
到了 64 位,两级远远不够。当前 Linux 的通用页表抽象其实是五级,自顶向下是:
- 全局页目录 PGD(Page Global Directory)
- 第四级目录 P4D(Page 4th Directory)
- 上层页目录 PUD(Page Upper Directory)
- 中间页目录 PMD(Page Middle Directory)
- 页表项 PTE(Page Table Entry)
在只用四级硬件分页的 x86-64 上,P4D 这一层会被“折叠”掉、不实际占用转换层级,所以你常听到的“四级页表”是这种折叠后的形态,而不是 Linux 里只定义了四级。
具体到 x86-64,目前主流是四级分页,用 48 位虚拟地址(寻址 256 TB)。一个 64 位虚拟地址这样拆:高 16 位是符号扩展位,接下来 PGD、PUD、PMD、PTE 各占 9 位(每级正好 512 项,2^9),最低 12 位是页内偏移(对应 4 KB 页)。每个页表项是 8 字节(64 位),512 项 × 8 字节 = 4 KB,每一级页表自己刚好占满一个页,设计得很整齐。
需要更大地址空间时,x86-64 提供了五级分页(LA57),把规范线性地址从 48 位扩到 57 位,物理地址最多 52 位。这里要注意两点:一是 Linux 文档把它描述为最多给用户空间 56 位虚拟地址,而且为了兼容那些把指针高位拿去做 tagging 的程序,内核默认不会主动在 47 位以上分配地址,除非应用显式请求;二是时间线别记岔,Linux 从 4.14(2017 年)起支持五级分页,是否启用取决于 CPU 和内核配置,Intel 这边明确支持 57 位虚拟、52 位物理地址的是第三代至强可扩展(Ice Lake 服务器平台,2021 年发布)。普通机器默认还是四级。
多级页表省了空间,却带来时间开销:原来查一次表,现在 64 位下要查四级,每多一级就多一次访存。一次内存访问背后藏着四五次查表访存,太亏了。
救场的还是局部性原理:程序在一段时间内反复访问的就那么几个页。那就把最常用的几个页表项,缓存到比内存快得多的硬件里。这块缓存就是 TLB(Translation Lookaside Buffer),中文叫快表、转址旁路缓存。它封装在 CPU 的 MMU 里。
有了 TLB,CPU 寻址时先查 TLB:
- 命中(TLB Hit),直接拿到物理页号,跳过整套多级页表的查找。
- 未命中(TLB Miss),才老老实实去查内存里的多级页表,查到之后再把这一项塞进 TLB,方便下次。
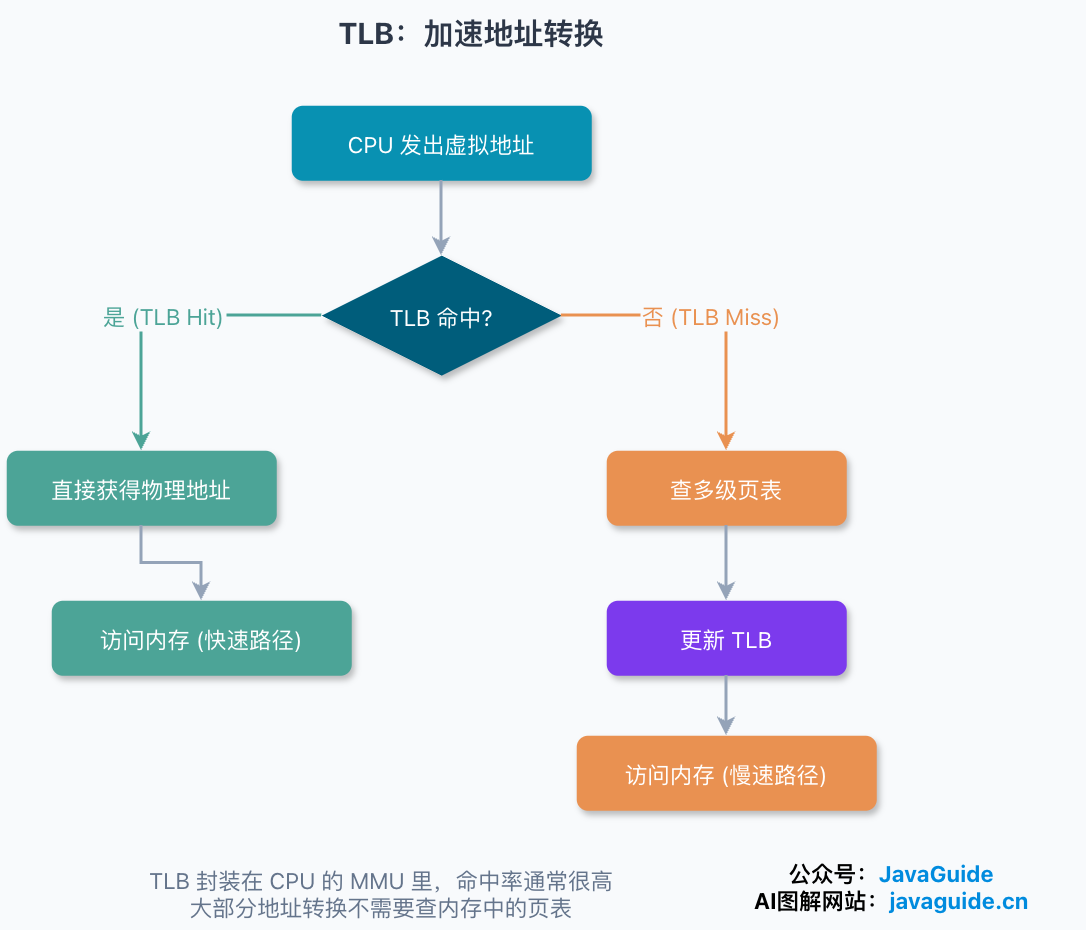
因为热点页就那么几个,TLB 命中率通常很高,所以多级页表带来的查表开销,大部分时候被 TLB 吃掉了。
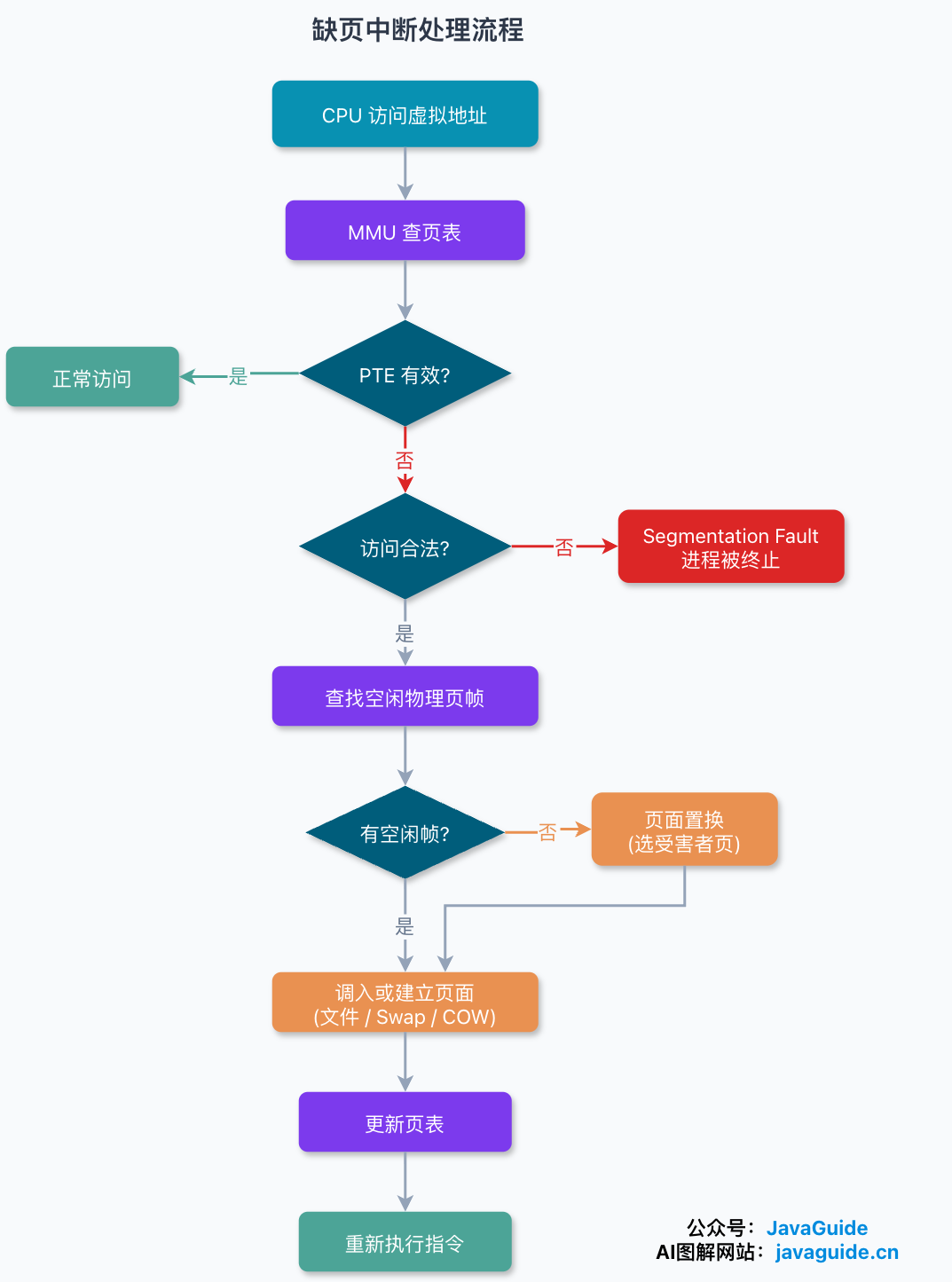
按需调页意味着:进程访问某个虚拟页时,这个页不一定在物理内存里。一旦 MMU 发现页表项指示该页不在内存(页表项里有个存在位 / present bit),就触发一次缺页中断,把控制权交给内核的缺页处理程序。
大致流程是这样:
- CPU 拿着虚拟地址查页表,发现目标页不在物理内存,触发缺页中断(一种硬件异常)。
- 进入内核态,缺页处理程序先判断这次访问是否合法。如果访问的是非法地址(比如野指针),就报段错误(Segmentation Fault),进程通常被杀掉。
- 合法的话,找一个空闲物理页帧。如果没有空闲帧,就得回收/置换一个“受害者”页:干净的文件页可以直接丢弃(要用时再从原文件读回),脏的文件页要先写回原文件,匿名页则在启用了 Swap 时写入交换空间——会不会真产生磁盘写,取决于页的类型和脏不脏。
- 把需要的页从磁盘(Swap 区或文件)读进物理内存,更新页表项,让它指向新的物理页帧。
- 返回用户态,重新执行刚才那条触发缺页的指令,这次就能正常访问了。
从 Linux 的性能统计角度,缺页主要分两类(getrusage 里也只有 ru_minflt 和 ru_majflt):
- 次缺页(Minor Page Fault):页其实已经在物理内存里了,只是当前进程的页表还没建立映射,比如多个进程共享的库;写时复制(COW)触发的页复制通常也算次缺页,因为它要新建或复制页面,但不用读盘。开销小。
- 主缺页(Major Page Fault):页确实不在内存,必须从磁盘(文件或 Swap)读进来,开销大。
至于访问非法地址(比如野指针),它同样会由硬件触发 page-fault 异常进内核,但内核判定非法后一般是给进程发 SIGSEGV,这属于错误处理,通常不和 minor/major 并列当成第三种性能统计类别。
如果物理内存太紧,系统大部分时间都在换入换出页,CPU 没怎么干正事,全在搬数据,这种恶性状态叫抖动(Thrashing)。
物理内存满了又要装新页,就得挑一个页换出去。挑得好,后面少缺页;挑得差,刚换出去的页转头又要用,白折腾。常见算法有这么几个。
OPT(最优置换):换出“未来最长时间内不会被访问”的页。它的缺页次数理论上最少,但需要预知未来,现实里实现不了,主要当衡量其他算法好坏的标尺。
FIFO(先进先出):维护一个队列,谁最早进来就先换谁出去。实现简单,但很蠢——一个页待得久不代表以后用不到,可能正是个热点页,结果刚踢走又得加载回来。
LRU(最近最少使用):换出“最久没被访问”的页。它赌的是局部性:最近用过的页,接下来大概率还会用。LRU 效果接近 OPT,但代价高:要么给每个页维护时间戳,要么用链表在每次访问时把页移到表头,硬件和软件开销都不小,纯软件实现很难扛住高频访问。
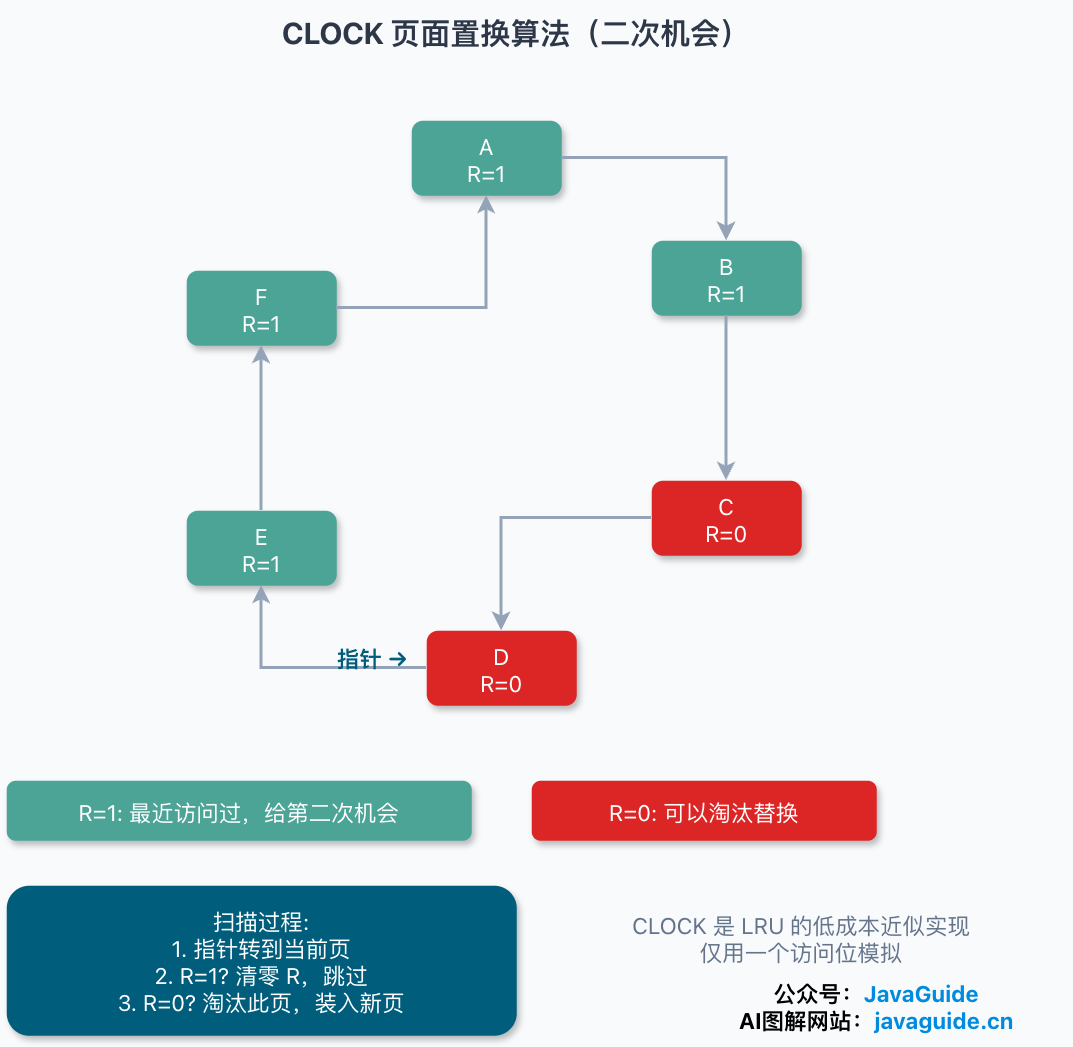
CLOCK(时钟 / 二次机会):LRU 的近似实现,用来绕开 LRU 的高成本。给每个页加一个访问位(reference bit)。所有页排成一个环,一根指针像时钟一样转。要换页时,指针指到谁就看它的访问位:是 1,说明最近用过,给它“第二次机会”,把访问位清 0,指针往下走;是 0,就换这一页出去。一个访问位加一圈环形扫描,就廉价地模拟出了“最近有没有被用过”。
LFU(最不经常使用):给每个页记访问次数,换出访问次数最少的页。它赌的是访问频率而非访问时间。问题是早期被频繁访问、后来不用的页,计数很高却赖着不走,所以实际中常配合计数衰减来用。
横向对比一下:
| 算法 | 换出依据 | 实现成本 | 效果 | 能不能落地 |
|---|---|---|---|---|
| OPT | 未来最久不用 | 无法实现 | 理论最优 | 只作基准 |
| FIFO | 进入时间最早 | 很低 | 一般,可能误伤热点页 | 能 |
| LRU | 最久未访问 | 高(时间戳/链表) | 接近 OPT | 纯软件较吃力 |
| CLOCK | 访问位 + 环形扫描 | 低 | 接近 LRU | 能,主流近似方案 |
| LFU | 访问次数最少 | 中(需计数) | 看场景 | 能,常配衰减 |
提一句别误会:上面这些是教科书算法,用来理解置换策略的思路。真实的 Linux 内核并不是直接在 OPT/FIFO/LRU/CLOCK 里挑一个,而是用活跃/非活跃双 LRU 链表、workingset、refault 检测这套近似机制,文件页和匿名页的回收策略也不一样,还受 NUMA、cgroup、内存水位影响。所以“Linux 用的就是 CLOCK”这种话不能直接下结论。
直觉上,物理内存的页帧越多,缺页应该越少。但 FIFO 会打脸:有时候增加页帧数,缺页次数反而变多了,这就是 Belady 异常(Belady's Anomaly),由 László Bélády 在 1960 年代发现。
用经典的访问串就能复现。访问序列 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5,跑 FIFO:
- 3 个页帧时,缺页 9 次。
- 4 个页帧时,缺页 10 次。
帧多了一个,缺页反而多了一次,违反直觉。
根因在于 FIFO 不满足栈性质(stack property):n 个页帧时驻留的页集合,不一定是 n+1 个页帧时驻留页集合的子集。一旦这个包含关系断了,加帧就可能踢错页。
满足栈性质的算法叫栈算法,它们对每个页的置换优先级与帧数无关,所以从数学上免疫 Belady 异常。OPT 和 LRU 都是栈算法,可以证明帧数增加时缺页只会减少或不变,不会反增。FIFO 不满足这个性质,所以会出问题。至于 LFU 会不会出现 Belady 异常,取决于它的频率统计方式和相同频率时的 tie-break 规则,不能笼统归进“免疫”那一类。
CLOCK 也别想当然:经典的二次机会/CLOCK 是 LRU 的近似,但并不具备 LRU 那种严格的栈性质(极端情况下所有访问位都是 1 时它会退化成 FIFO),所以不能因为它“近似 LRU”就推出它必然免疫 Belady 异常。稳妥的结论是:FIFO 存在会触发 Belady 异常的访问序列,OPT 和 LRU 一定不会,CLOCK、LFU 这类要看具体定义,别简单背成“近似 LRU 就一定免疫”。
记住一个结论就够用了:Belady 异常是 FIFO 这类非栈算法的毛病,遇到“加内存性能反降”的诡异现象,先怀疑置换策略,而不是怀疑内存条坏了。
虚拟内存不是只活在操作系统课本里,往上层走几步就能撞见它。
mmap 与零拷贝:mmap() 把文件直接映射到进程的虚拟地址空间,读文件变成访问内存。映射建立时并不真的把文件读进来,等你访问到某一页才触发缺页、按页加载,这正是按需调页。它省掉了一次从内核缓冲区到用户缓冲区的拷贝,是零拷贝方案里常用的一招。
Redis 的内存与碎片:Redis 是纯内存数据库,但它申请的内存最终也要落到物理页上。内存分配器(默认 jemalloc)按固定大小档位(size class)分配,会有空间浪费。它和分页里“不足一页也占一页”在“分配粒度大于实际用量”这点上很像,但一个发生在用户态分配器、一个发生在操作系统分页层,产生位置和治理方式都不同,不能直接当成同一种碎片。Redis 持久化时 fork 出子进程做快照,靠的也是写时复制(Copy-On-Write)——父子进程先共享同一批物理页,谁写谁才触发页复制,背后还是页表那套机制。
JVM 的堆:JVM 向操作系统申请的堆,也是一片虚拟地址空间。大堆会拉大页表要覆盖的范围,配大页(HugePage / 2 MB 大页)能减少页表项数量、缓解 TLB 压力,对降低 GC 期间的访存开销有帮助。GC 扫描对象时反复跳来跳去、访问局部性差,更直接的代价是 cache miss 和 TLB miss 增多;只有当相关页还没驻留、被回收过,或系统本身内存吃紧时,才会进一步表现为缺页。这也是大堆调优要盯 TLB 的原因。
往下是硬件的页表和 TLB,往上是数据库、JVM、零拷贝,中间这层虚拟内存,是把它们串起来的公共地基。
如果面试官问“为什么需要虚拟内存”,别只背“为了隔离”。可以这样答:虚拟内存先把进程看到的地址和真实物理地址隔开,让每个进程都像在独占一片连续内存;MMU 再配合页表把虚拟地址翻译成物理地址。这样做有三个直接收益:进程之间互不踩内存,程序不用关心物理内存摆放位置,操作系统还能按需分配、换页和做 COW。
如果继续追问“分页解决了什么”,重点放在分段和分页的差别上。分段按逻辑模块切,长度不固定,容易产生外部碎片,整理起来也重;分页把虚拟地址空间和物理内存都切成固定大小的页,页表记录“虚拟页号 → 物理页帧”的映射,基本消除了外部碎片,但会有少量内部碎片。多级页表的作用不是让查找更快,而是让没用到的地址空间不用真的建页表,靠空间换结构。
问到 TLB 和缺页中断时,可以按这条线说:CPU 先查 TLB,命中就直接拿到物理页号;没命中再走多级页表。页表项如果显示页不在内存,就触发缺页异常,内核判断访问是否合法,合法才分配页帧、必要时回收旧页、从文件或 Swap 调入页面,最后更新页表并重新执行那条指令。minor fault 通常不用读盘,major fault 要读盘,非法访问则会走到 SIGSEGV。
页面置换算法不用背一堆名词,抓住评价标准就行:换出去的页后面越晚用越好。OPT 最优但做不到,LRU 接近 OPT 但实现成本高,CLOCK 用访问位给 LRU 做近似,FIFO 简单但可能出现 Belady 异常。真实 Linux 不是照搬某个教科书算法,而是用活跃/非活跃 LRU、workingset、refault 等机制做近似回收。